深度学习推荐系统实战
深度学习推荐系统实战
老师:王喆
基础架构篇
1. 技术架构:深度学习推荐系统的经典技术架构长啥样?
2. Sparrow RecSys:我们要实现什么样的推荐系统?
03 | 深度学习基础:你打牢深度学习知识的地基了吗?
神经元是神经网络的基础结构,它参照生物学中神经元的构造,抽象出带有输入输出和激活函数的数学结构。
而神经网络是通过将多个神经元以串行、并行、全连接等方式连接起来形成的网络,神经网络的训练方法是基于链式法则的梯度反向传播。
特征工程篇
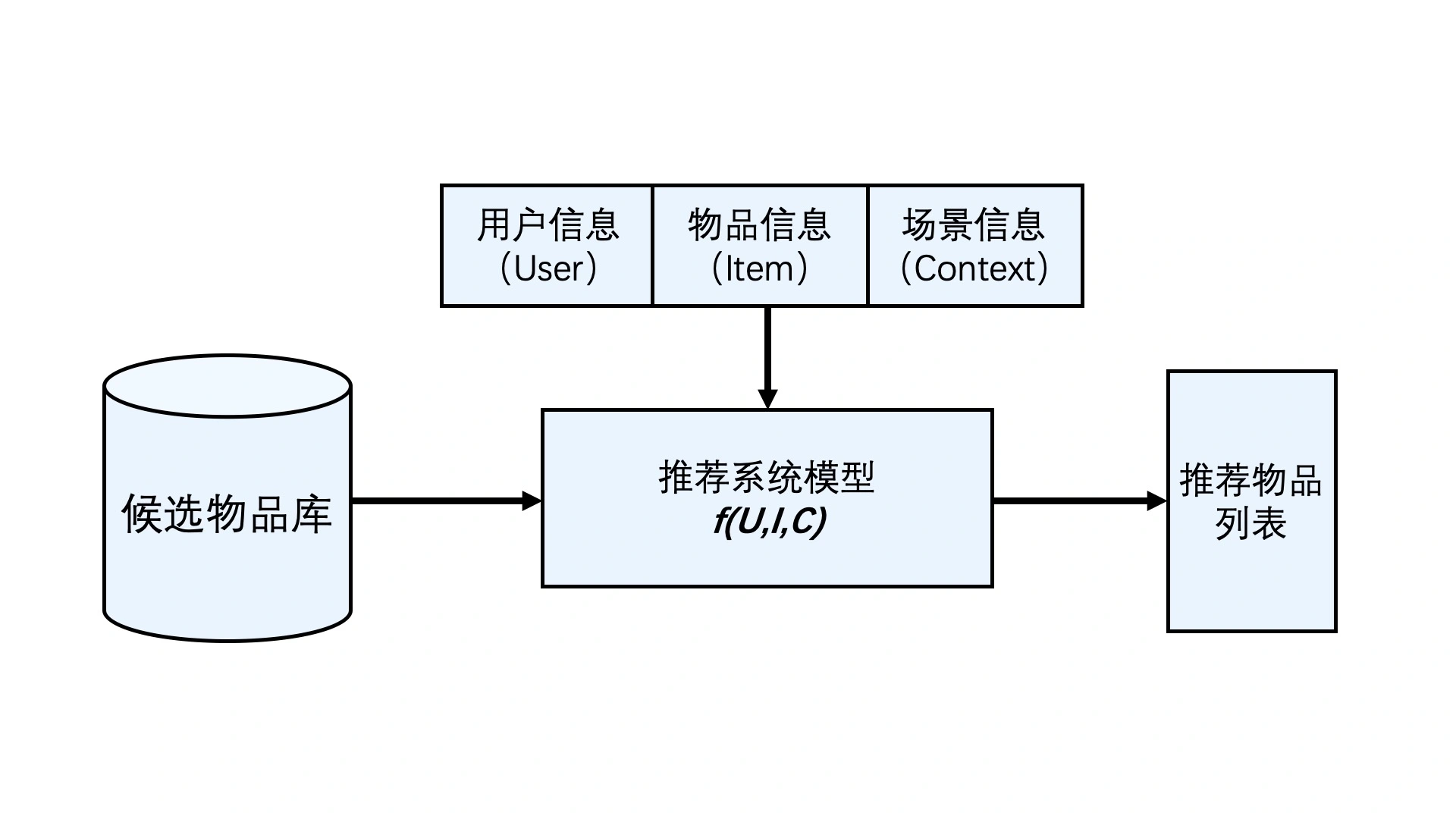
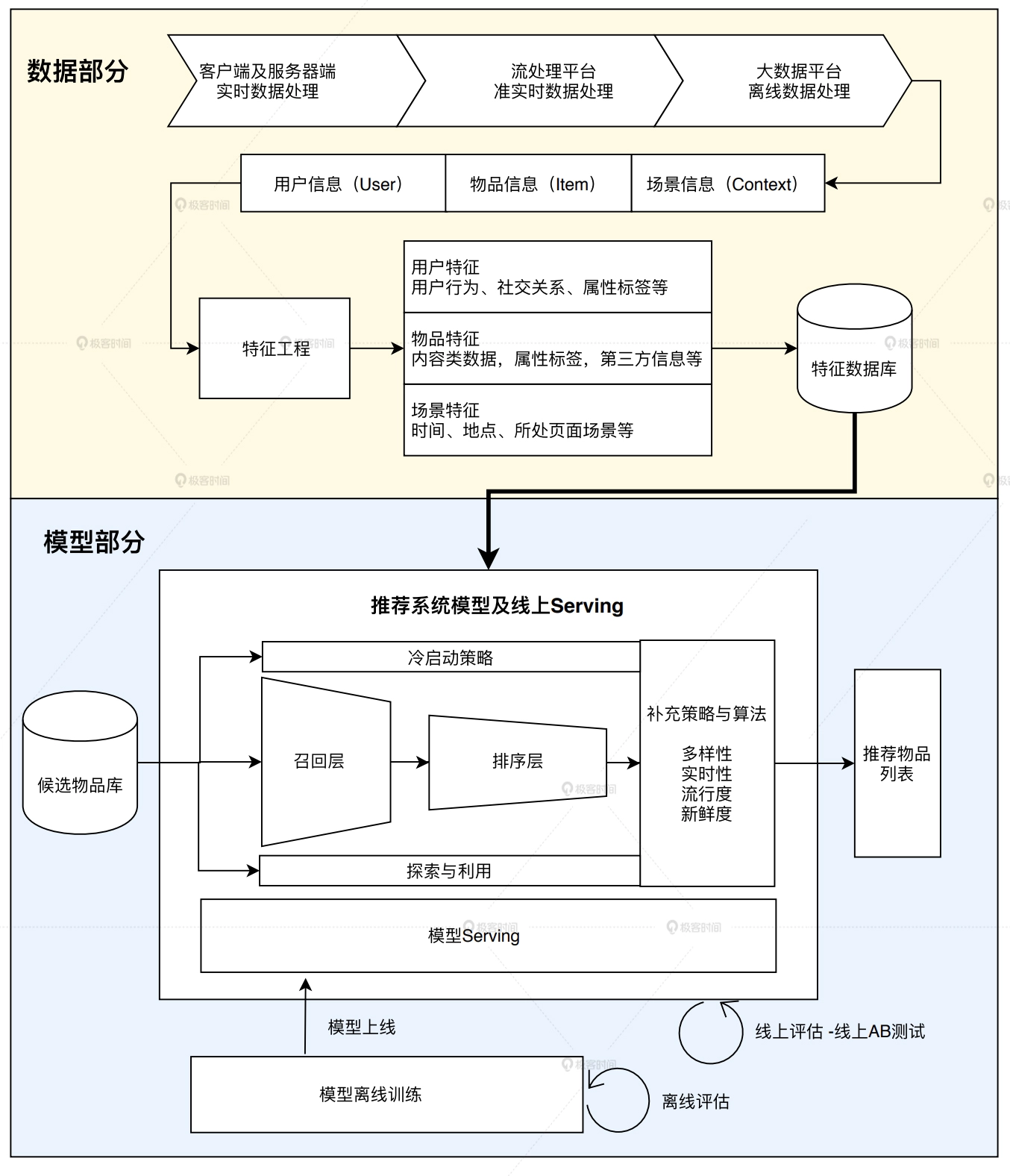
04 | 特征工程:推荐系统有哪些可供利用的特征?
什么是特征工程
特征工程就是利用工程手段从“用户信息”、“物品信息”、“场景信息”中提取特征的过程。
- 如何挑选出有用的特征
- 如何将各种特征信息转换成模型可用的数值向量。
构建特征工程的基本原则是什么
特征其实是对某个行为过程相关信息的抽象表达。
信息往往会损失:
- 推荐行为和场景包含大量图像视频等数据,无法全部存储。
- 具体推荐场景有很多冗余信息,可能影响模型泛化,或收效甚微。
尽可能地让特征工程抽取出的一组特征,能够保留推荐环境及用户行为过程中的所有“有用“信息,并且尽量摒弃冗余信息。
拿电影推荐举例:要素和特征的关系。
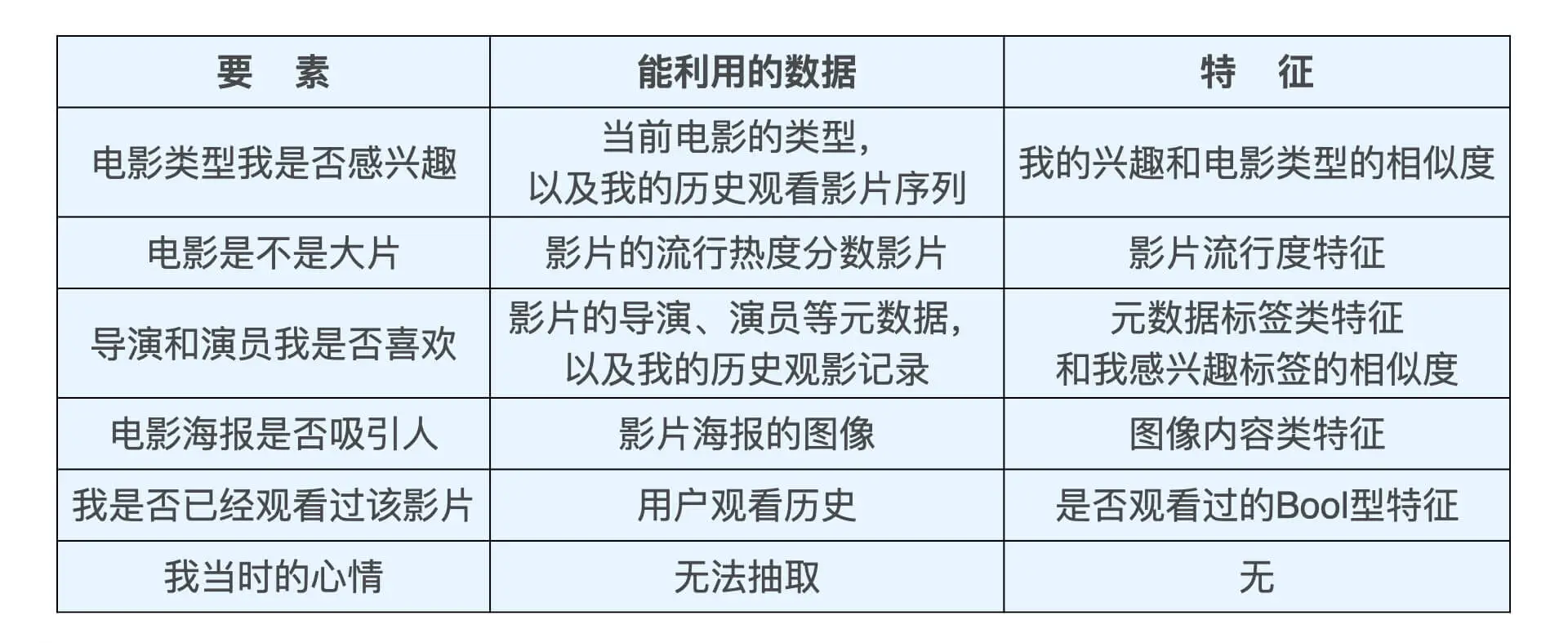
在已有的、可获得的数据基础上,“尽量”保留有用信息是现实中构建特征工程的原则。
推荐系统中重用的特征有哪些
- 用户行为数据 最常用和关键的。分为显性反馈和隐性反馈。
- 用户关系数据 分为显性和隐性,或者说强关系和弱关系。 强关系:互相关注、好友、同一社群。弱关系:点赞同一视频。
- 属性、标签类数据内容类数据
- 场景信息、上下文信息 时间、地点、GPS等
05 | 特征处理:如何利用Spark解决特征处理问题?
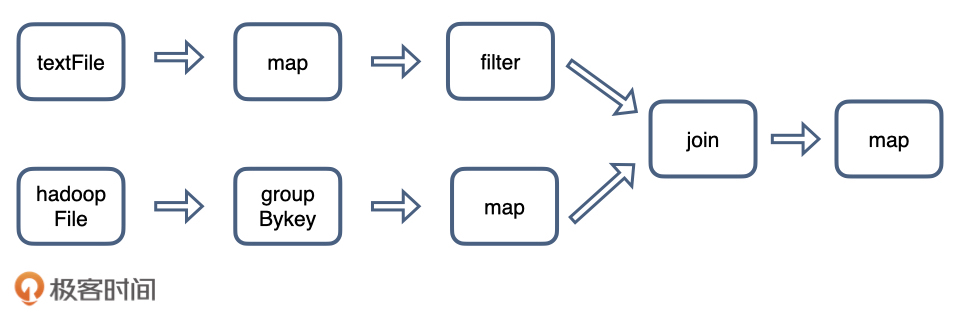
关键是理解哪些需要操作并行。 那么要理解哪些操作要shuffle和reduce(混洗、聚合)。
注意:shuffle 操作需要在不同计算节点之间进行数据交换,非常消耗计算、通信及存储资源,因此 shuffle 操作是 spark 程序应该尽量避免的。
问题:
- 经典的特征处理方法有什么?
- Spark 是如何实现这些特征处理方法的?
这里我们再用一句话总结 Spark 的计算过程:Stage 内部数据高效并行计算,Stage 边界处进行消耗资源的 shuffle 操作或者最终的 reduce 操作。
如何利用One-Hot编码处理类别型特征
特征分类:
- 类别、ID型特征
- 数值型特征
对于数值型特征我们直接转成数值向量即可,但是对于类别、ID型特征我们应该如何处理?
这里我们就要用到 One-hot 编码(也被称为独热编码),它是将类别、ID 型特征转换成数值向量的一种最典型的编码方式。 它通过将其他所有置为0,只自己维度置为1. 比如: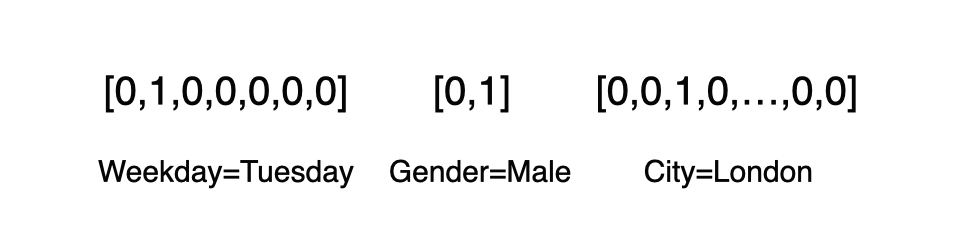
比如long型电影ID也可用One-Hot转成多维度向量表示。
One-hot 编码也可以自然衍生成 Multi-hot 编码(多热编码)。比如,对于历史行为序列类、标签特征等数据来说,用户往往会与多个物品产生交互行为,或者一个物品被打上多个标签,这时最常用的特征向量生成方式就是把其转换成 Multi-hot 编码。
数值型特征的处理 - 归一化和分桶
为什么要处理特征,两个角度,特征的尺度和特征的分布。
特征的尺度: 比如两个特征尺度: f1[0, 10]、f2[0, 10000],如果不加处理,则模型受到f2的影响会很大,f1基本没影响,所以我们希望把尺度拉平到一个 范围,通常[0, 1],这就是所以的归一化。
我们经常会用分桶的方式来解决特征值分布极不均匀的问题。所谓 “分桶(Bucketing)”, 就是将样本按照某特征的值从高到低排序,然后按照桶的数量找到分位数,将样本分到各自的桶中,再用桶 ID 作为特征值。
分桶的方法:等距,等频,模型分桶,改变样本的特征分布,让其有区分度
在 Spark MLlib 中,分别提供了两个转换器 MinMaxScaler 和 QuantileDiscretizer,来进行归一化和分桶的特征处理。
使用方法和之前介绍的 OneHotEncoderEstimator 一样,都是先用 fit 函数进行数据预处理,再用 transform 函数完成特征转换
处理方法不止上面提到:比如在经典的 YouTube 深度推荐模型中,将观看时间间隔(time since last watch)和视频曝光量(#previous impressions)这两个特征 分别做平方和开方处理,成为多个特征。
这些操作与分桶操作一样,都是希望通过改变特征的分布,让模型能够更好地学习到特征内包含的有价值信息。 但由于我们没法通过人工的经验判断哪种特征处理方式更好,所以索性把它们都输入模型,让模型来做选择。
进行特征处理的一个原则,就是特征处理并没有标准答案。
总结
06 | Embedding基础:所有人都在谈的Embedding技术到底是什么?
什么是 Embedding?
Embedding就是用一个数值向量“表示”一个对象的方法。
重要性:
- 首先,Embedding 是处理稀疏特征的利器。
- 其次,Embedding 可以融合大量有价值信息,本身就是极其重要的特征向量
因此我们才说,Embedding 技术在深度学习推荐系统中占有极其重要的位置,熟悉并掌握各类流行的 Embedding 方法是构建一个成功的深度学习推荐系统的有力武器。 这两个特点也是我们为什么把 Embedding 的相关内容放到特征工程篇的原因,因为它不仅是一种处理稀疏特征的方法,也是融合大量基本特征,生成高阶特征向量的有效手段。
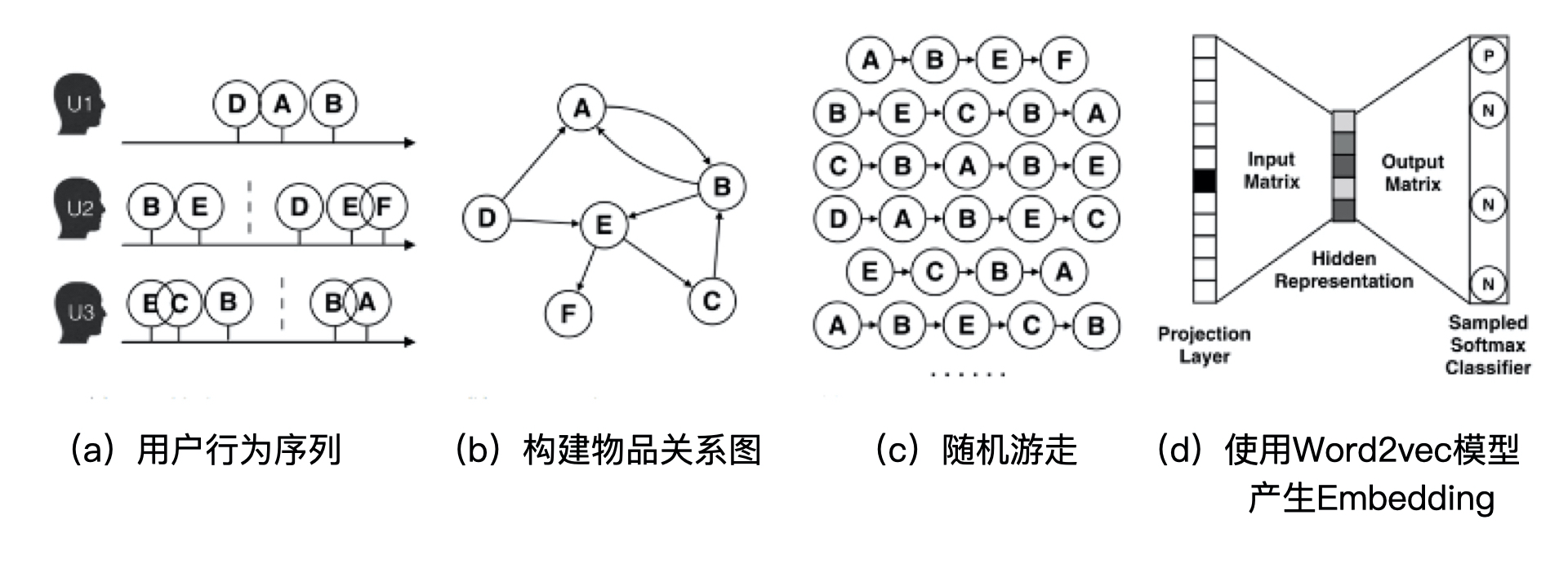
07 | Embedding进阶:如何利用图结构数据生成Graph Embedding?
我们互联网有很多图数据,问题应该如何转换成embedding呢。
互联网中有哪些图结构数据?
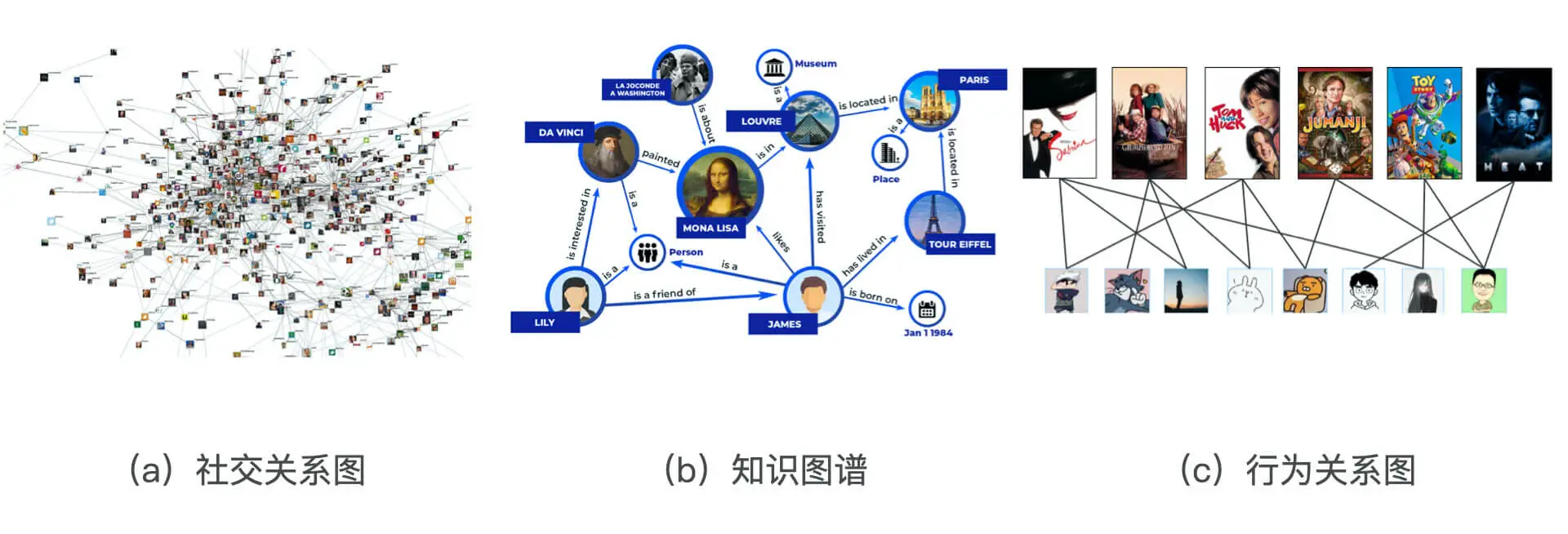
社交网络、知识图谱、行为关系等。
基于随机游走的 Graph Embedding 方法:Deep Walk
在同质性和结构性间权衡的方法,Node2vec
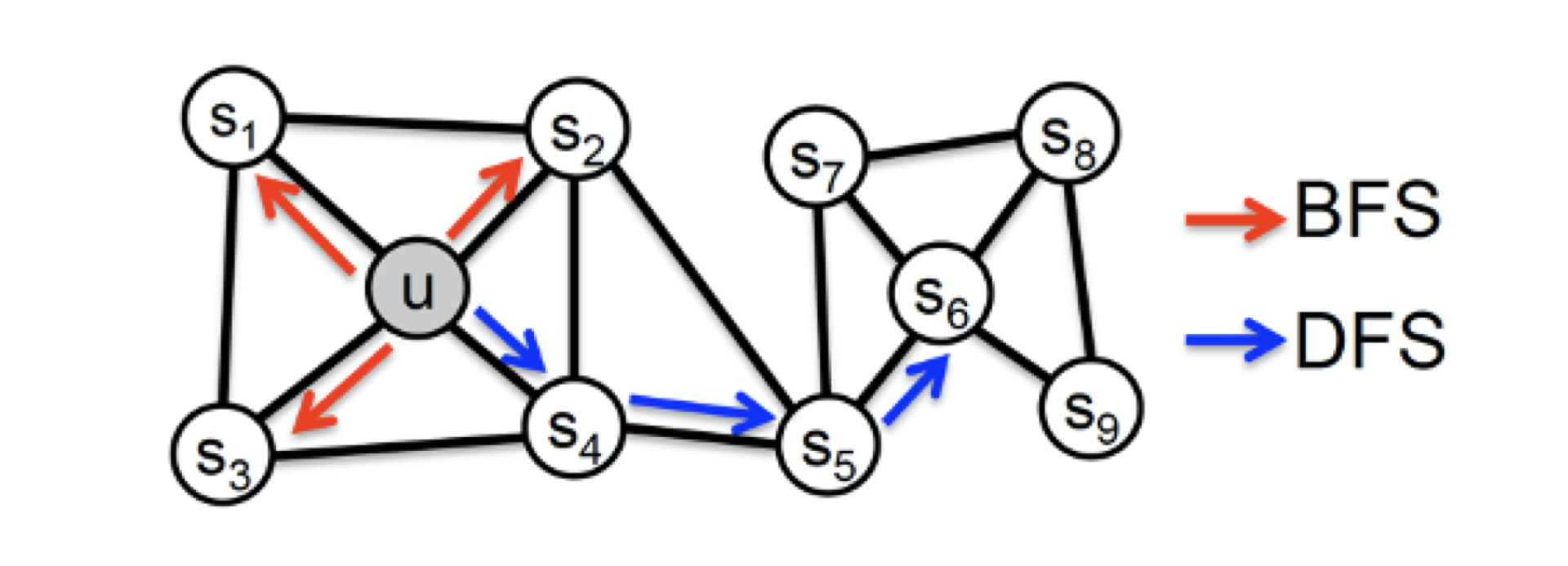
- “同质性”指的是距离相近节点的 Embedding 应该尽量近似, BFS
- “结构性”指的是结构上相似的节点的 Embedding 应该尽量接近,DFS
那在 Node2vec 算法中,究竟是怎样控制 BFS 和 DFS 的倾向性的呢?其实,它主要是通过节点间的跳转概率来控制跳转的倾向性。
08 | Embedding实战:如何使用Spark生成Item2vec和Graph Embedding?
线上服务篇
09 | 线上服务:如何在线上提供高并发的推荐服务?
在线部分: 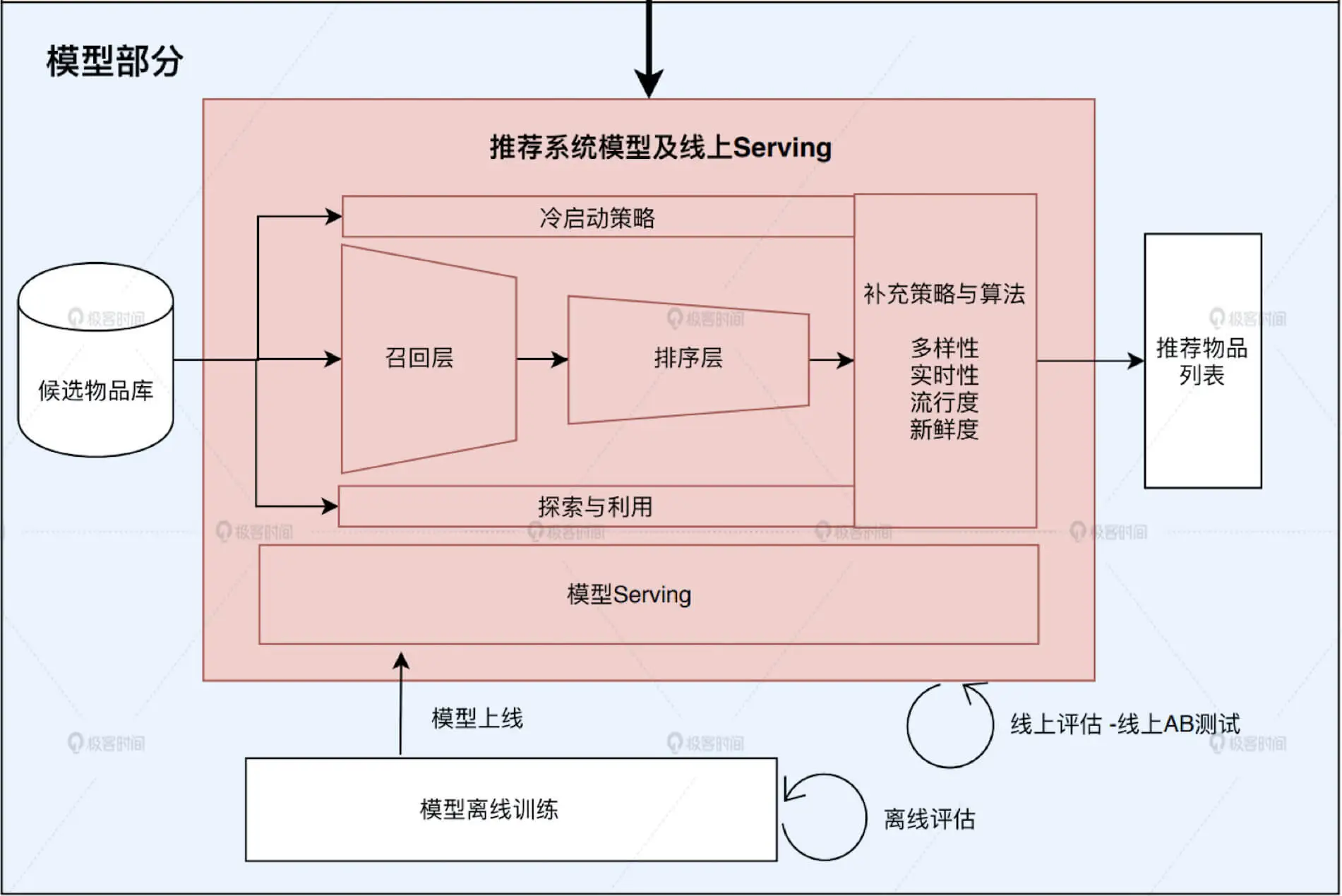
三个重要机制:
- 负载均衡
- 缓存
- 推荐服务降级机制
<{这里快速看看即可,作者对工程的理解一般}>
10 | 存储模块:如何用Redis解决推荐系统特征的存储问题?
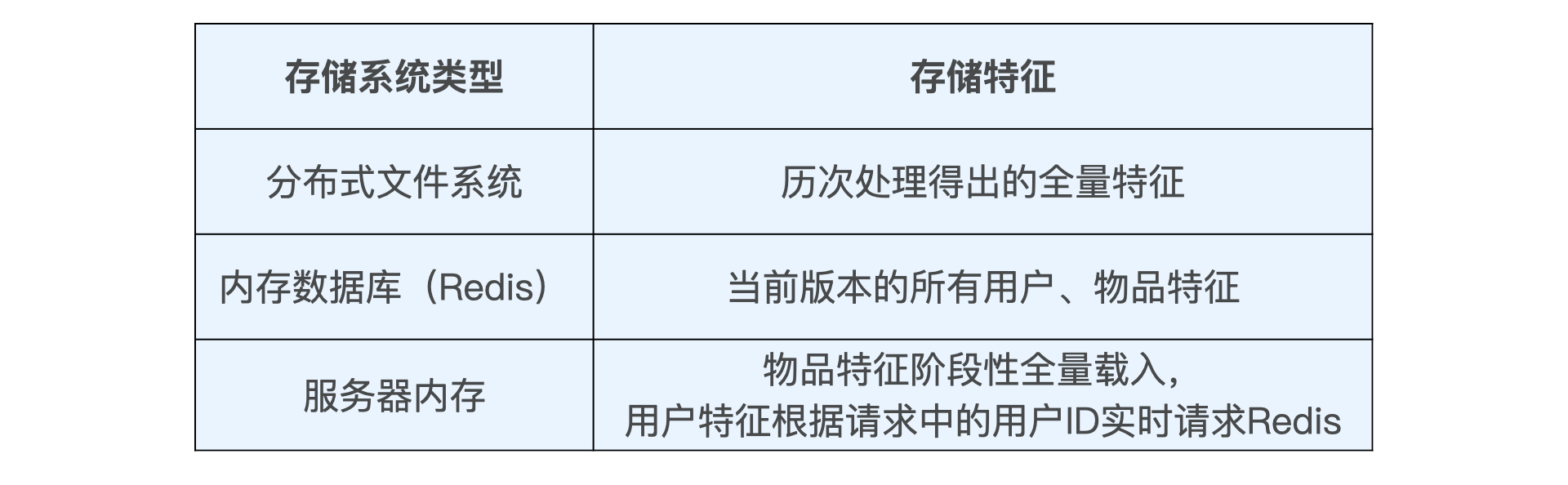
总的来说,推荐系统存储模块的设计原则就是“分级存储,把越频繁访问的数据放到越快的数据库甚至缓存中,把海量的全量数据放到廉价但是查询速度较慢的数据库中”。
在SparrowRecsys中,我们使用基础的文件系统保存全量的离线特征和模型数据, 用 Redis 保存线上所需特征和模型数据, 使用服务器内存缓存频繁访问的特征。
存储方案
11 | 召回层:如何快速又准确地筛选掉不相关物品?
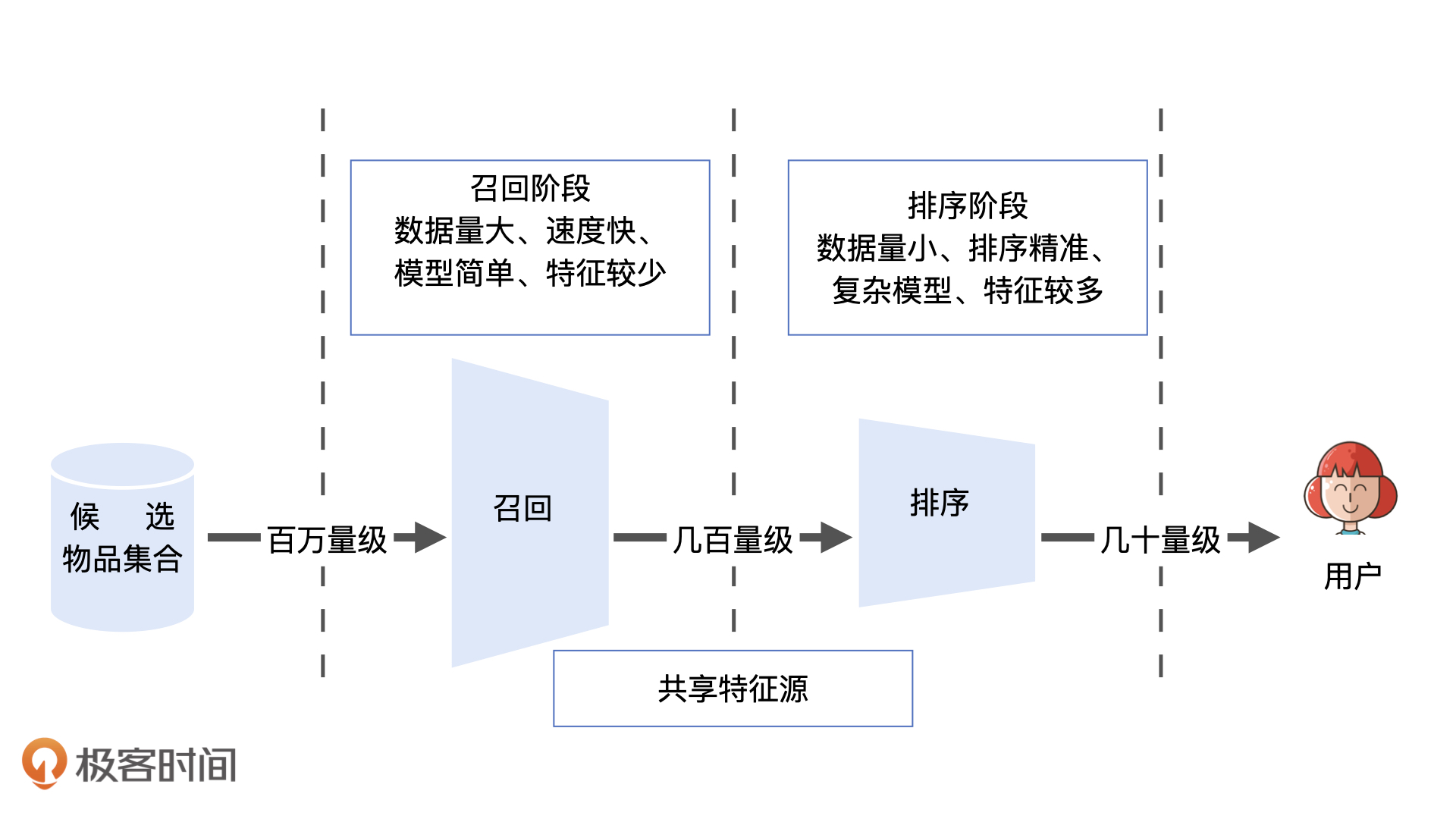
在推荐物品候选集规模非常大的时候,我们该如何快速又准确地筛选掉不相关物品,从而节约排序时所消耗的计算资源呢?
召回的作用
召回位于系统的线上服务模块。
单策略召回
单策略召回指的是,通过制定一条规则或者利用一个简单模型来快速地召回可能的相关物品。
多路召回
所谓“多路召回策略”,就是指采用不同的策略、特征或简单模型,分别召回一部分候选集,然后把候选集混合在一起供后续排序模型使用的策略。
在实现的过程中,为了进一步优化召回效率,我们还可以通过多线程并行、建立标签 / 特征索引、建立常用召回集缓存等方法来进一步完善它。
缺点:
- 每一路召回的数量需要人工参与调整,需要经过大量AB测试
- 因为策略之间的信息和数据是割裂的,所以我们很难综合考虑不同策略对一个物品的影响。
基于embedding的召回
优点
- 多路融合到一路embedding。多路召回中使用的“兴趣标签”“热门度”“流行趋势”“物品属性”等信息都可以作为 Embedding 方法中的附加信息(Side Information),融合进最终的 Embedding 向量中 。
- Embedding 召回的评分具有连续性。(不是相互割裂的)
步骤: 第一步,我们获取用户的 Embedding。
第二步,我们获取所有物品的候选集,并且逐一获取物品的 Embedding,计算物品 Embedding 和用户 Embedding 的相似度。
第三步,我们根据相似度排序,返回规定大小的候选集。
12 | 局部敏感哈希:如何在常数时间内搜索Embedding最近邻?
何快速找到与一个 Embedding 最相似的 Embedding?这直接决定了召回层的执行速度,进而会影响推荐服务器的响应延迟。
业界解决近似 Embedding 搜索的主要方法,局部敏感哈希。
换一个角度思考这个问题,由于用户和物品的 Embedding 同处一个向量空间内,因此召回与用户向量最相似的物品 Embedding 向量这一问题,其实就是在向量空间内搜索最近邻的过程。
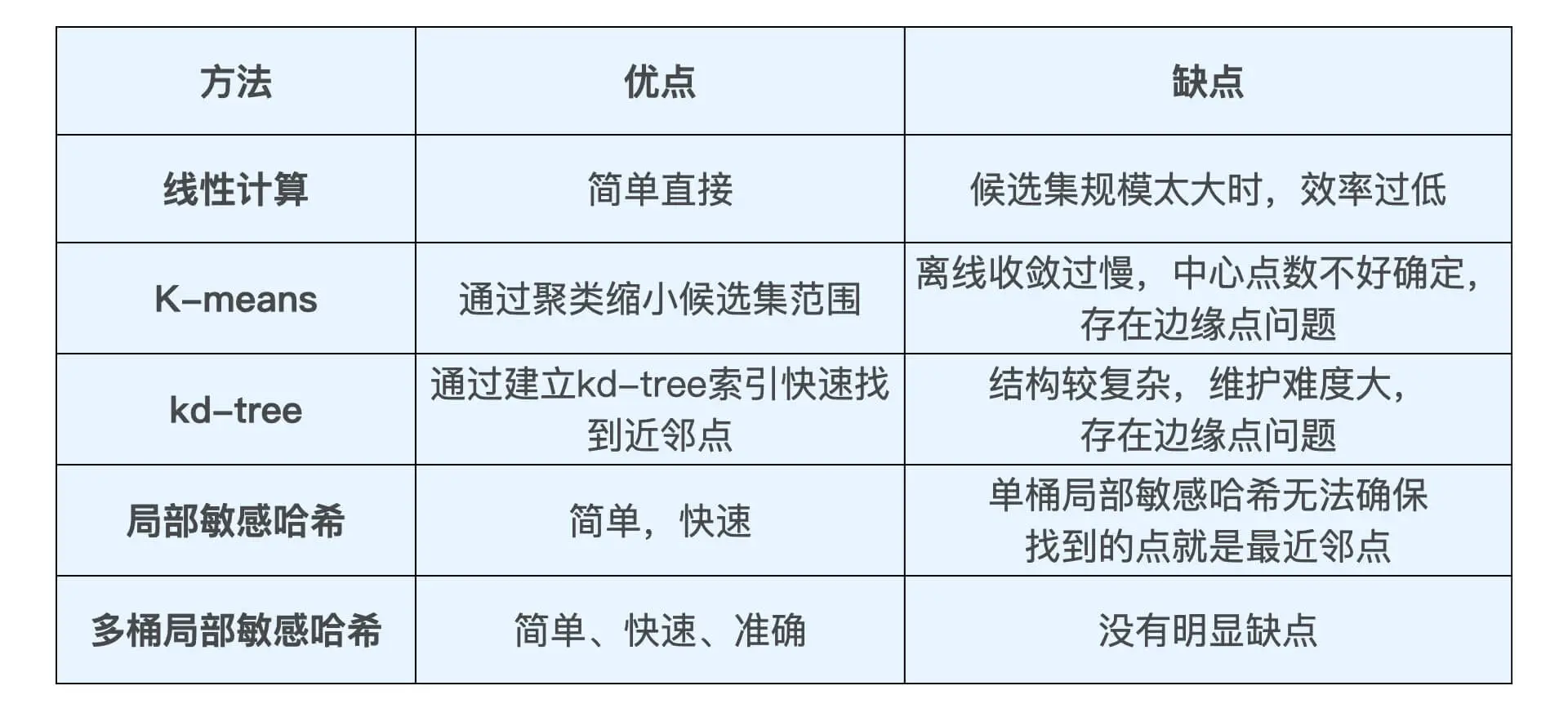
最近邻搜索的:
- 聚类 k-means
- 索引 KD-tree
- 局部敏感哈希 LSH
局部敏感哈希
原理
局部敏感哈希的基本思想是希望让相邻的点落入同一个“桶”,这样在进行最近邻搜索时,我们仅需要在一个桶内,或相邻几个桶内的元素中进行搜索即可。 如果保持每个桶中的元素个数在一个常数附近,我们就可以把最近邻搜索的时间复杂度降低到常数级别。
- 多桶:我们可以采用多个哈希函数进行分桶。
- 针对不同距离定义,分桶函数定义也不一样。核心是我们怎么通过分桶方式保留部分距离信息,同时大幅降低紧邻点候选集。
<{什么是内积操作。}>
多桶策略
这里有些经验的策略,建议以后读。
局部敏感哈希实践
在将电影 Embedding 数据转换成 dense Vector 的形式之后,
我们使用 Spark MLlib 自带的 LSH 分桶模型 BucketedRandomProjectionLSH(我们简称 LSH 模型)来进行 LSH 分桶。
事实上,在一些超大规模的最近邻搜索问题中,索引、分桶的策略还能进一步复杂。如果你有兴趣深入学习, 我推荐你去了解一下Facebook 的开源向量最近邻搜索库 FAISS,这是一个在业界广泛应用的开源解决方案。
总结
13 | 模型服务:怎样把你的离线模型部署到线上?
在业界的生产环境中,模型需要在线上运行,实时地根据用户请求生成模型的预估值。
模型服务:将模型部署到线上,并实时进行模型推断(Inference)。
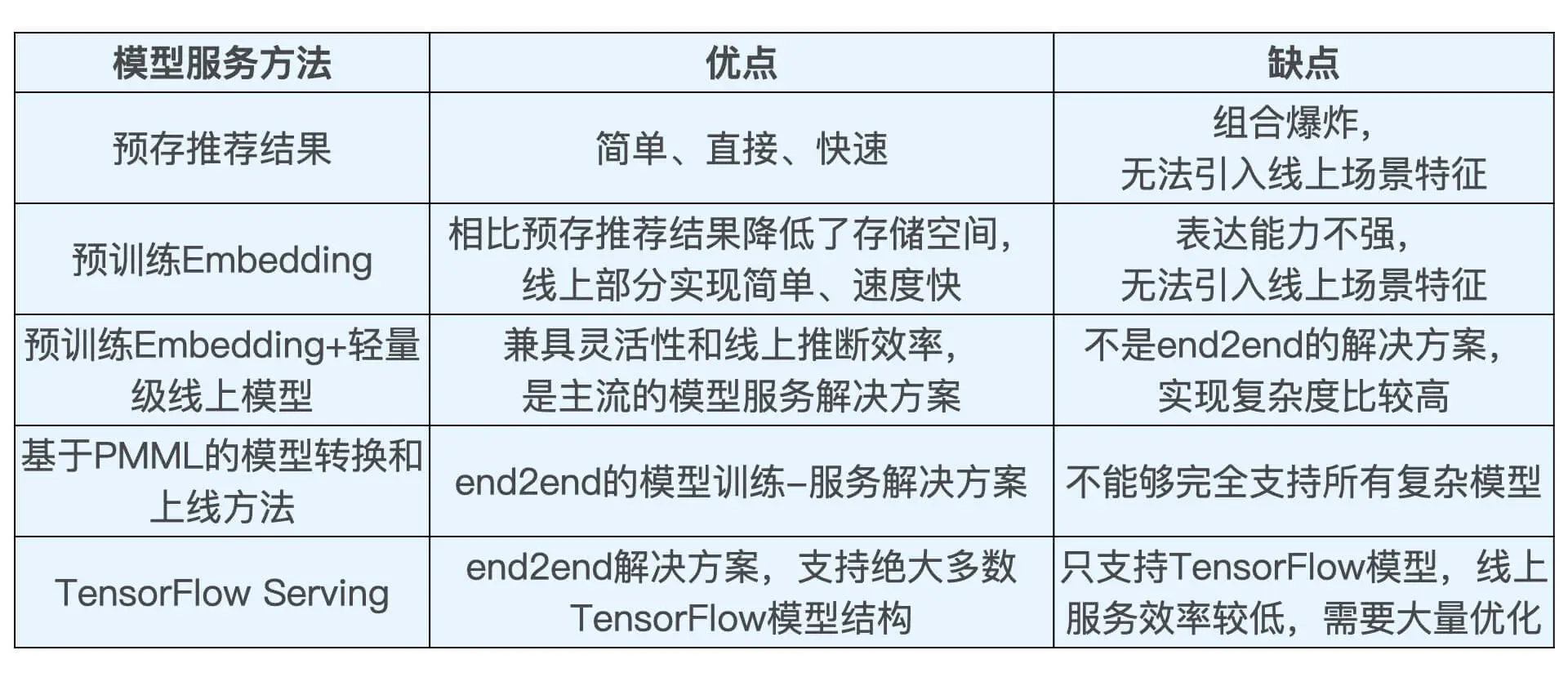
业界主流的模型服务方法
四种:
- 预存推理结果或embedding结果
- 预训练embedding+轻量级线上模型
- PMML模型
- TensorFlow Serving
预存推荐结果或 Embedding 结果
直接预存推荐结果: 
预存embedding:
我们先离线训练好 Embedding,然后在线上通过相似度运算得到最终的推荐结果。
优点:线上推断过程非常简单快速,因此,预存Embedding的方法是业界经常采用的模型服务手段。 缺点:缺点其实和直接存推荐结果的缺点是一样的。
预训练 Embedding+ 轻量级线上模型
这也是常用手段。
因为上一种方法只用相似度计算,太简单,有局限性。
实现:用复杂深度学习网络离线训练生成 Embedding,存入内存数据库,再在线上实现逻辑回归或浅层神经网络等轻量级模型来拟合优化目标”。
这是主流模式,比如百度的cube存储embedding,predictor进行预估。阿里MIMN。
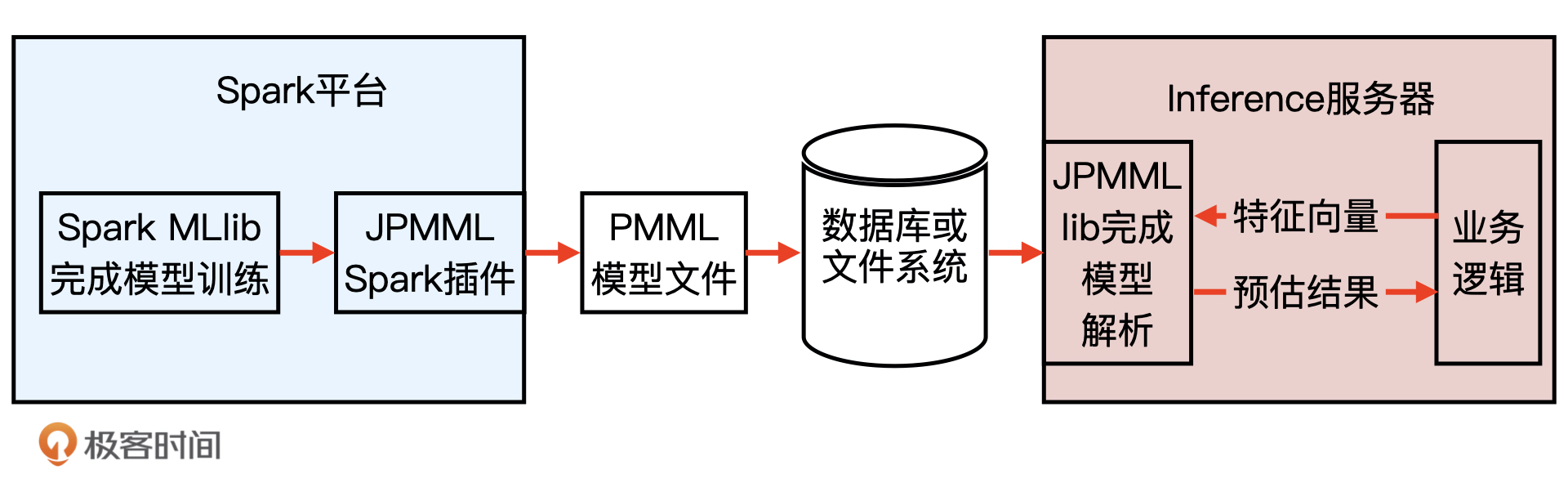
利用 PMML 转换和部署模型
离线训练完模型之后什么都不用做,直接部署模型的方式。
PMML 的全称是“预测模型标记语言”(Predictive Model Markup Language, PMML),它是一种通用的以 XML 的形式表示不同模型结构参数的标记语言。 在模型上线的过程中,PMML 经常作为中间媒介连接离线训练平台和线上预测平台。
优点:
- end2end训练和部署
TensorFlow Serving
从整体工作流程来看,TensorFlow Serving 和 PMML 类工具的流程一致,它们都经历了模型存储、模型载入还原以及提供服务的过程。
优点:
- 易用性
- 支持复杂模型
缺点:
- 需要进行性能优化
- 只限于tensorFlow
实战搭建 TensorFlow Serving 模型服务
总结
14 | 融会贯通:Sparrow RecSys中的电影相似推荐功能是如何实现的?
如何实现相似电影推荐功能?
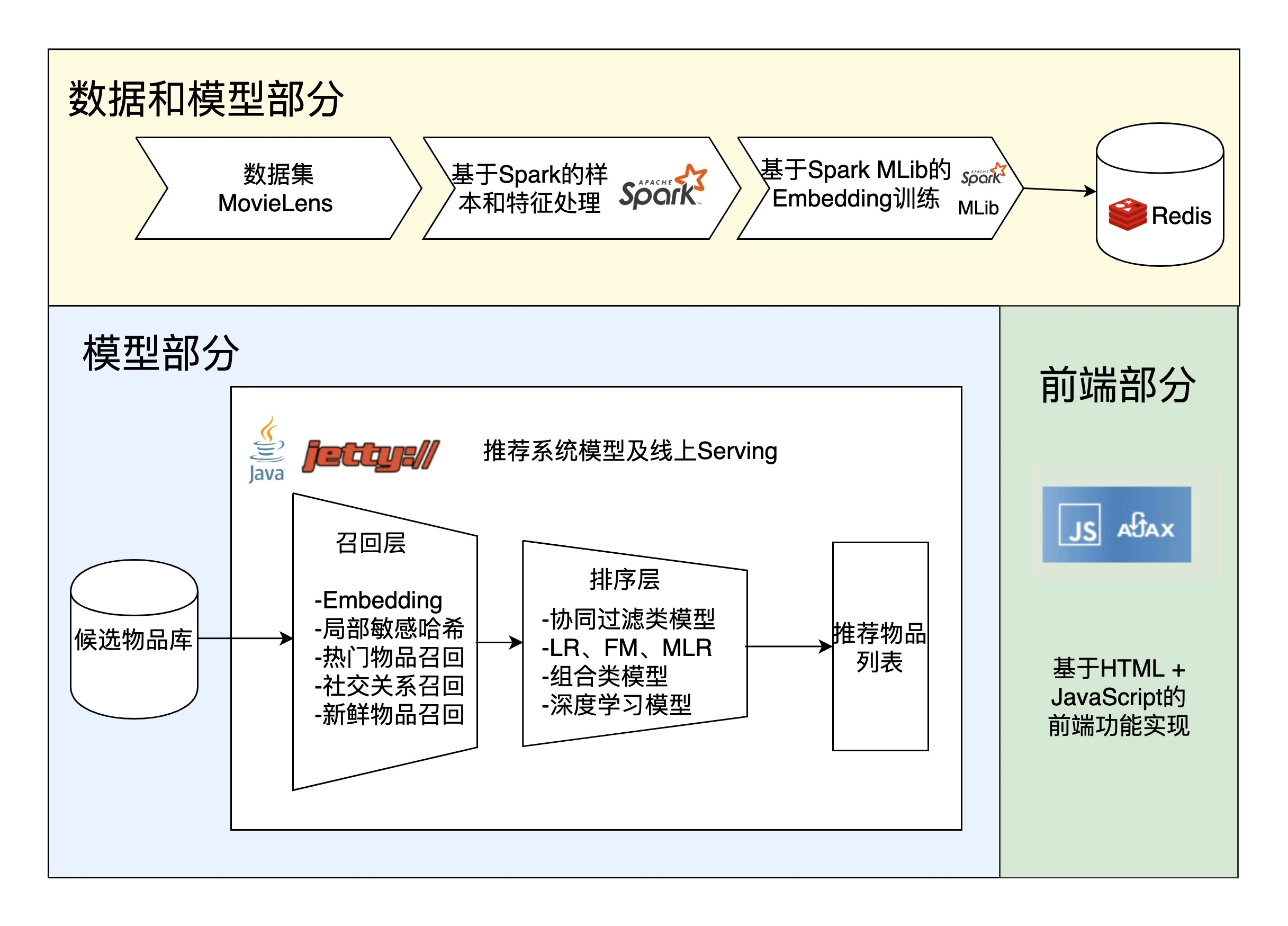
1. 数据和模型部分
2. 线上服务部分
3. 前端部分
相似电影推荐的结果和初步分析
- 人肉测试
- 指定Ground truth
- 利用商业指标进行评估。
总结
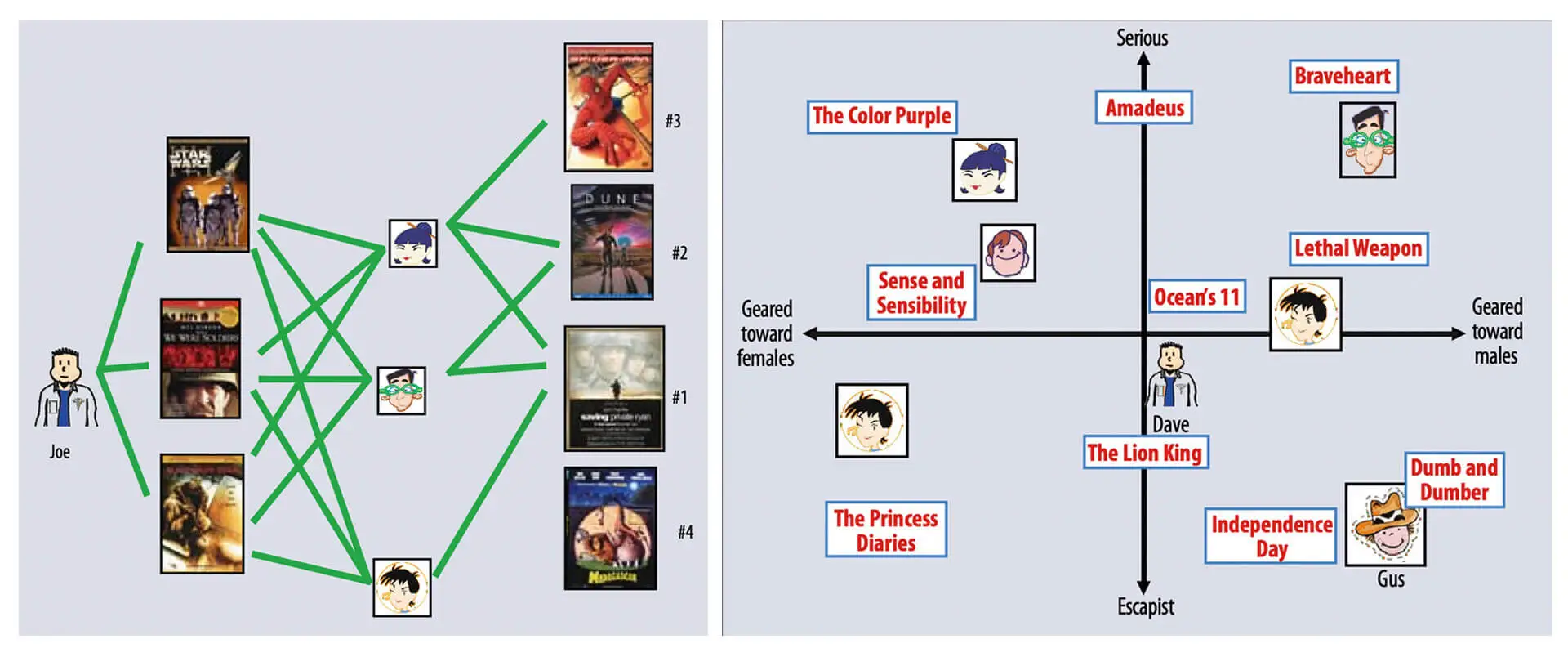
15 | 协同过滤:最经典的推荐模型,我们应该掌握什么?
推荐模型是推荐系统皇冠上的明珠。
协同过滤算法基本原理
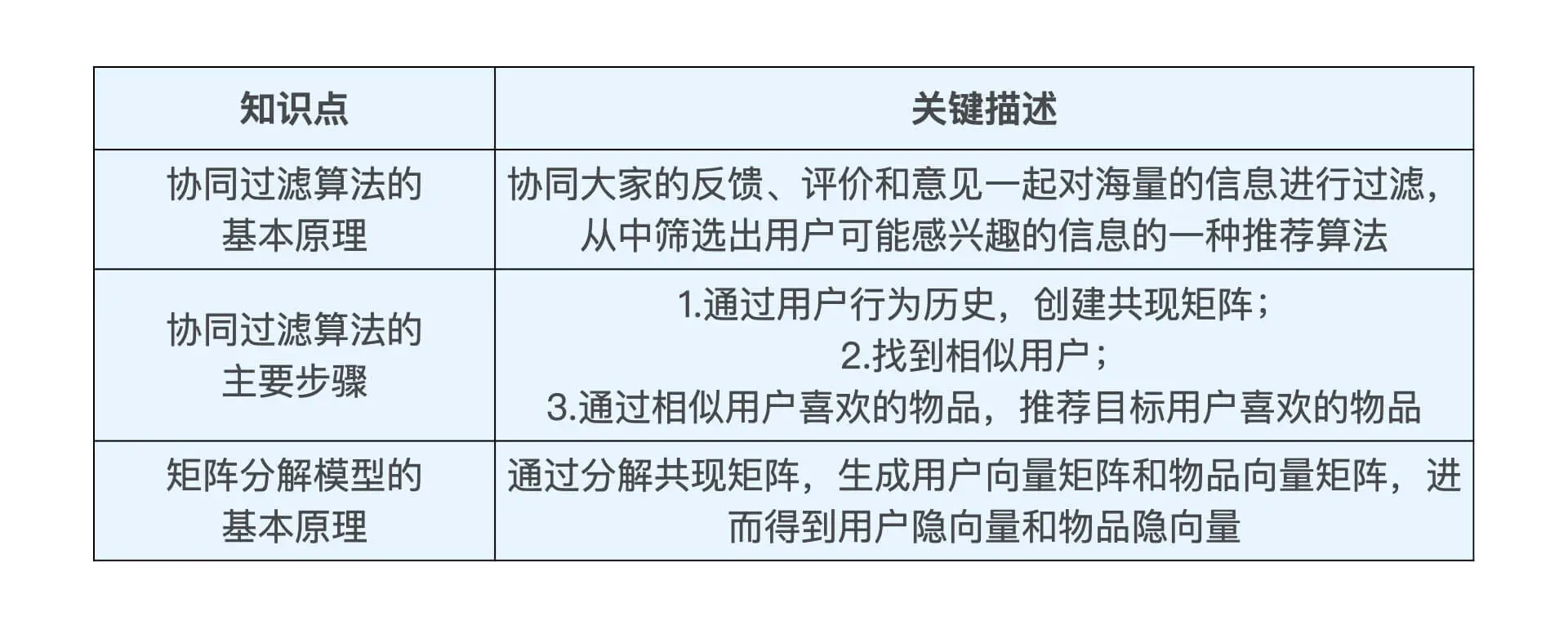
协同过滤算法,就是一种完全依赖用户和物品之间行为关系的推荐算法。我们从它的名字“协同过滤”中,也可以窥探到它背后的原理, 就是 “协同大家的反馈、评价和意见一起对海量的信息进行过滤,从中筛选出用户可能感兴趣的信息”。
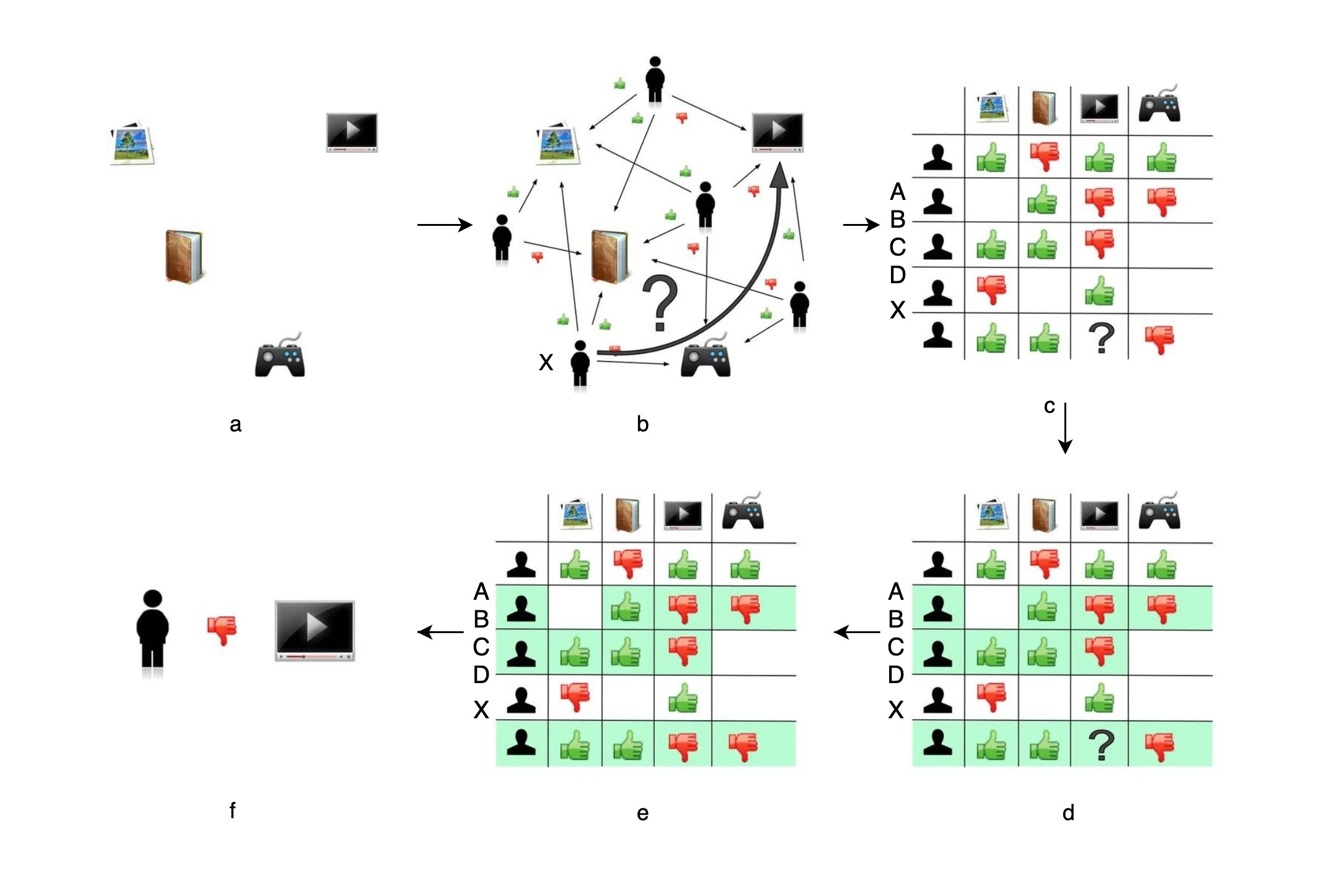
优点:
缺点:
- 比较稀疏 (优化:通过生成用户与物品的相似隐向量来)
计算用户相似度
用户评分预测

Wu,s是用户u和用户s的相似度,Rs,p是用户s对物品p的评分。
矩阵分解算法的原理
算法原理:为每一个用户和视频生成一个隐向量,将用户和视频定位到隐向量的表示空间,距离相近的用户和物品说明兴趣点接近。
历史:
五年前的推荐系统,矩阵分解是很主流的技术方案。但是矩阵分解没法引入除用户行为外的其他特征,深度学习出来之后就逐渐被取代了。
总结
16 | 深度学习革命:深度学习推荐模型发展的整体脉络是怎样的?
当下,模型很多,但是没有统一的模板应用哪一种。
作者认为,只有建立起一个比较全面的深度学习模型知识库,我们才能在工作中做出正确的技术选择,为模型的下一步改进方向找到思路。
深度学习对推荐系统的影响
- 深度学习的强拟合能力
- “欠拟合”指的是模型复杂度低,无法很好地拟合训练集数据的现象。
- 过拟合”是指模型在训练集上的误差很小,但在测试集上的误差较大的现象
- 深度学习模型结构的灵活性
- 不同深度模型的结构
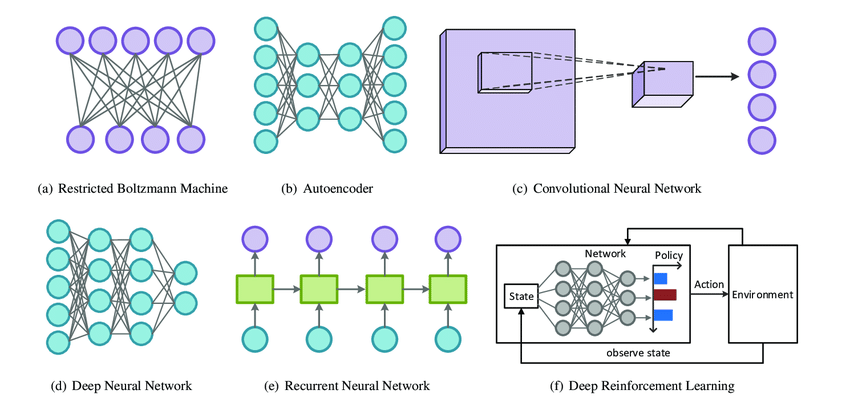
- 不同深度模型的结构
深度学习推荐模型的演化关系图
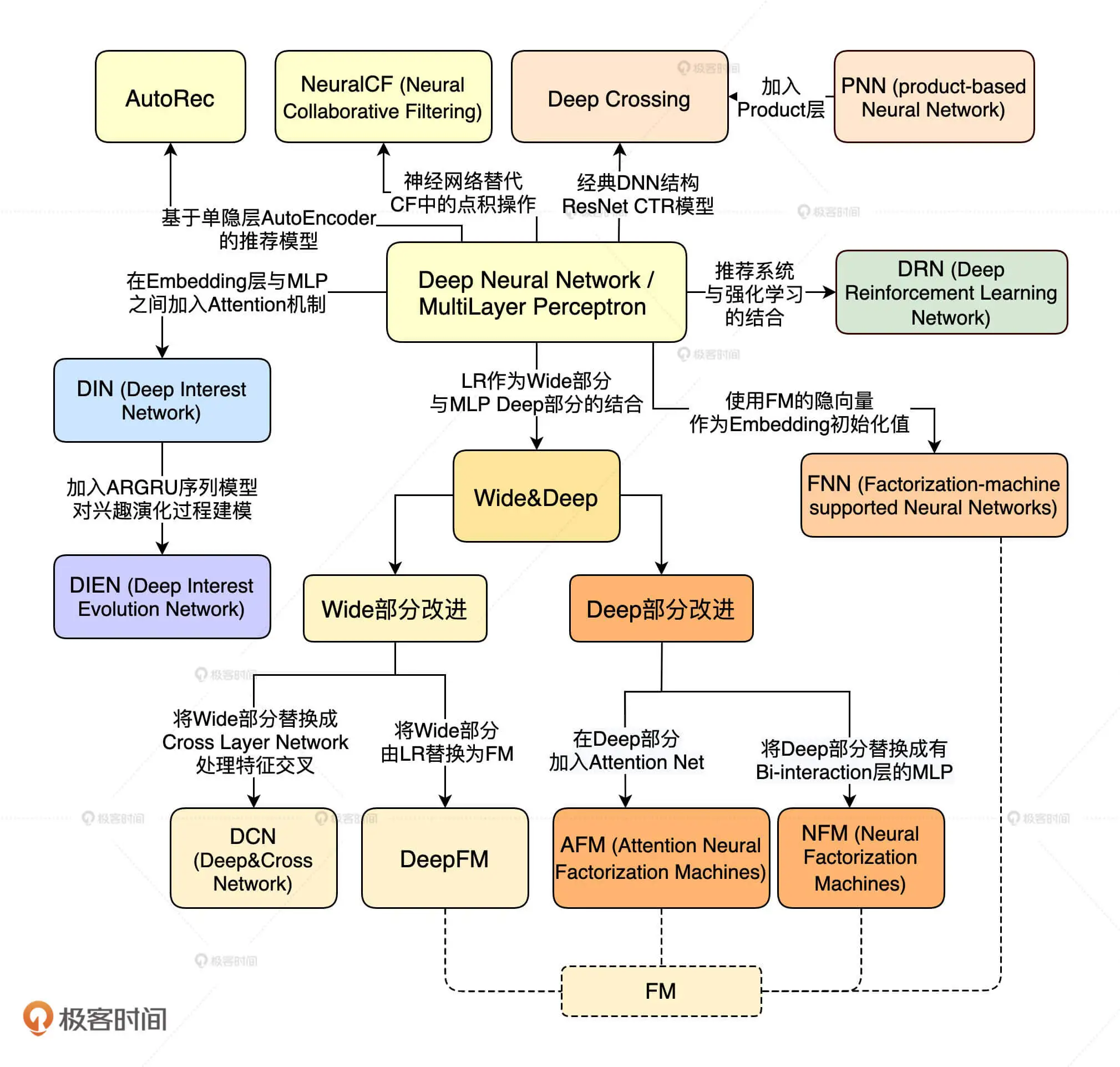
- “多层感知机”是整个演化图的核心。
- Embedding+MLP 的结构是最经典,也是应用最广的深度学习推荐模型结构。
- Wide&Deep 是业界又一得到广泛应用的深度推荐模型。
模型的四个改进方向:
- 改变神经网络的复杂程度。
- 改变特征交叉方式
- 多种模型组合应用
- 让深度推荐模型和其他领域进行交叉。
总结
模型实战准备(一) | TensorFlow入门和环境配置
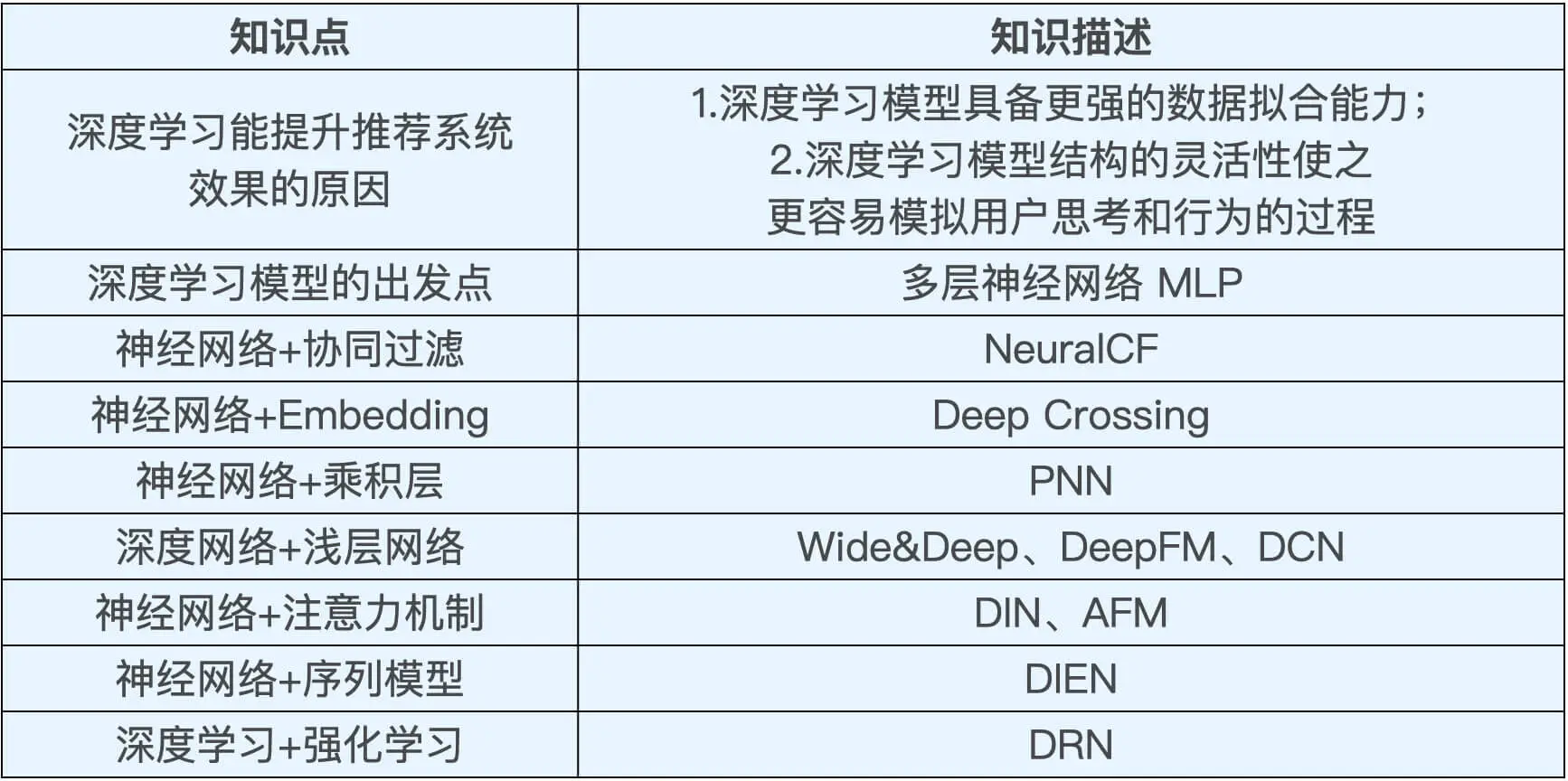
什么是TensorFlow
TensorFlow是由Google Brain团队开发的深度学习平台。2015年首次发布。
基本原理:就是根据深度学习模型架构构建一个有向图,让数据以张量的形式在其中流动起来。
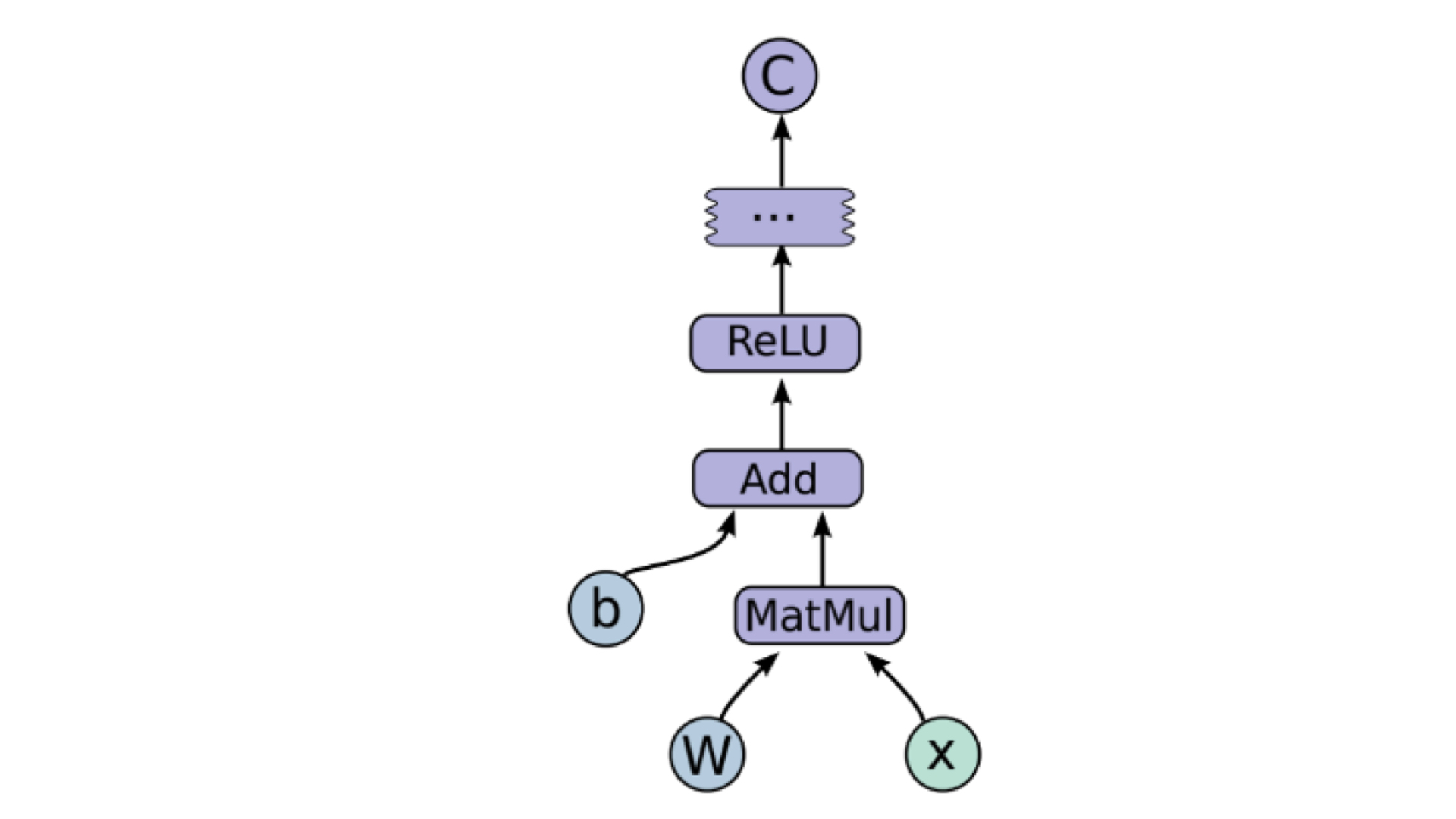
事实上,任何复杂模型都可以抽象为操作有向图的形式。
测试模型
步骤:
- 载入数据
- 定义模型
- 训练数据
- 评估模型
总结
模型实战准备(二) | 模型特征、训练样本的处理
17 | Embedding+MLP:如何用TensorFlow实现经典的深度学习模型?
18|Wide&Deep:怎样让你的模型既有想象力又有记忆力?
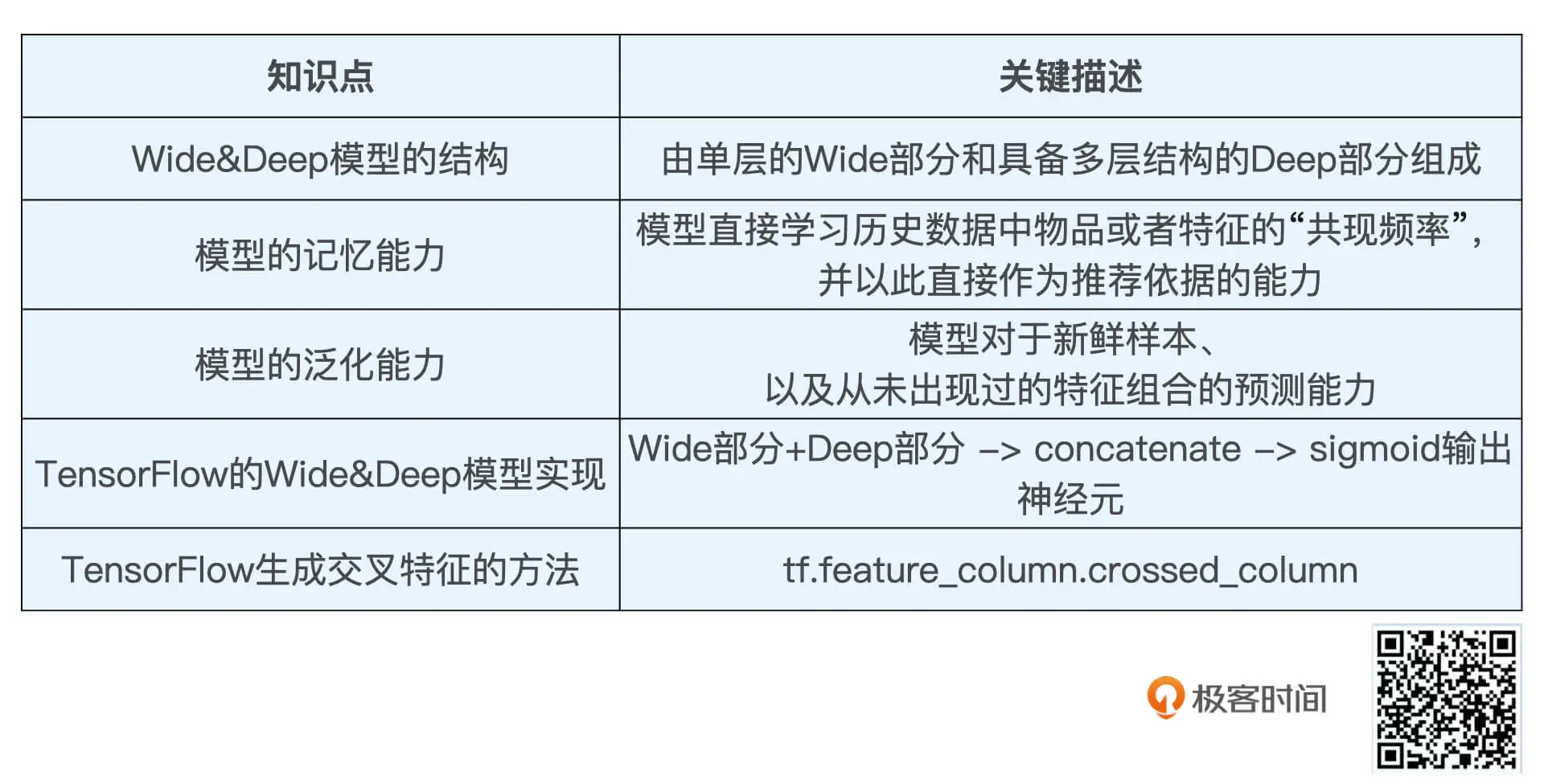
模型结构
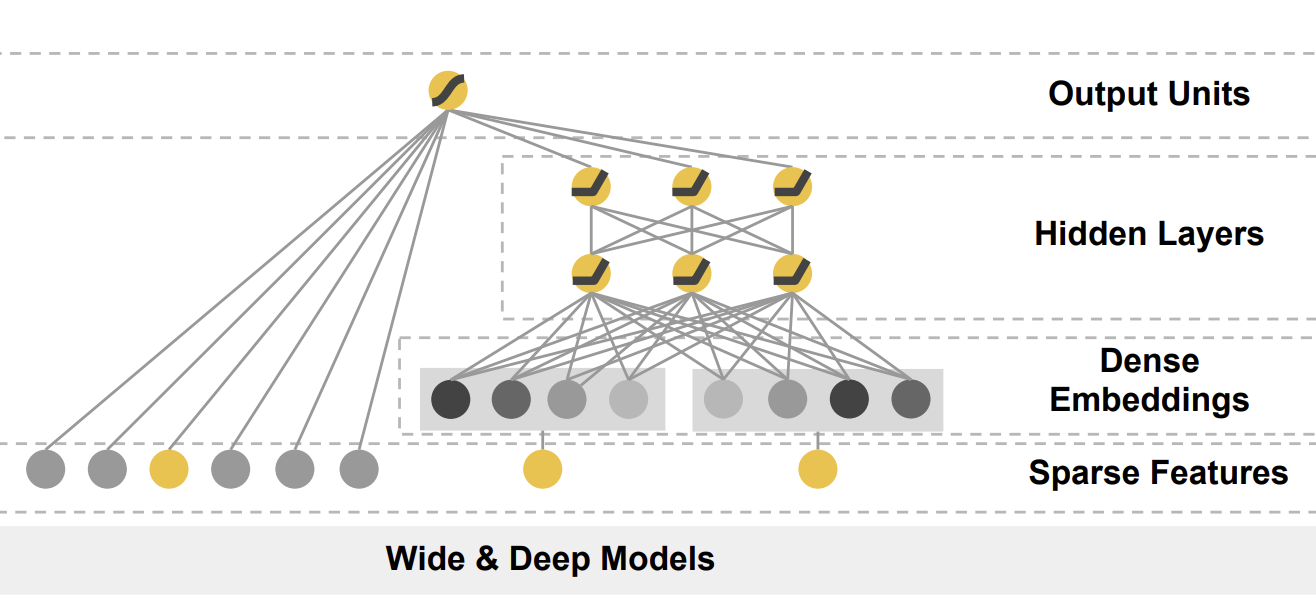
模型的记忆能力
模型的泛化能力
19|NeuralCF:如何用深度学习改造协同过滤?
NeuralCF模型: 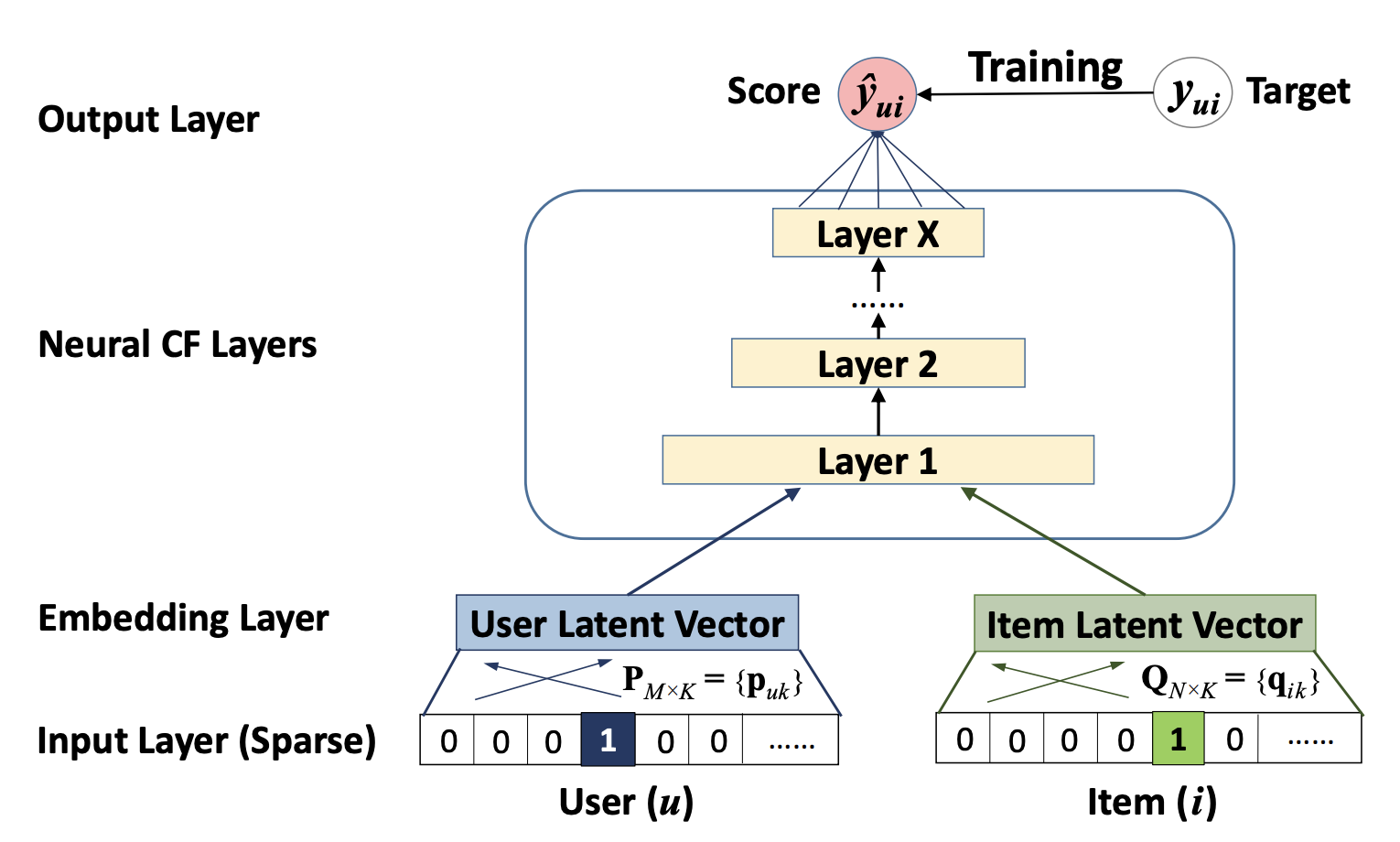
双塔结构: 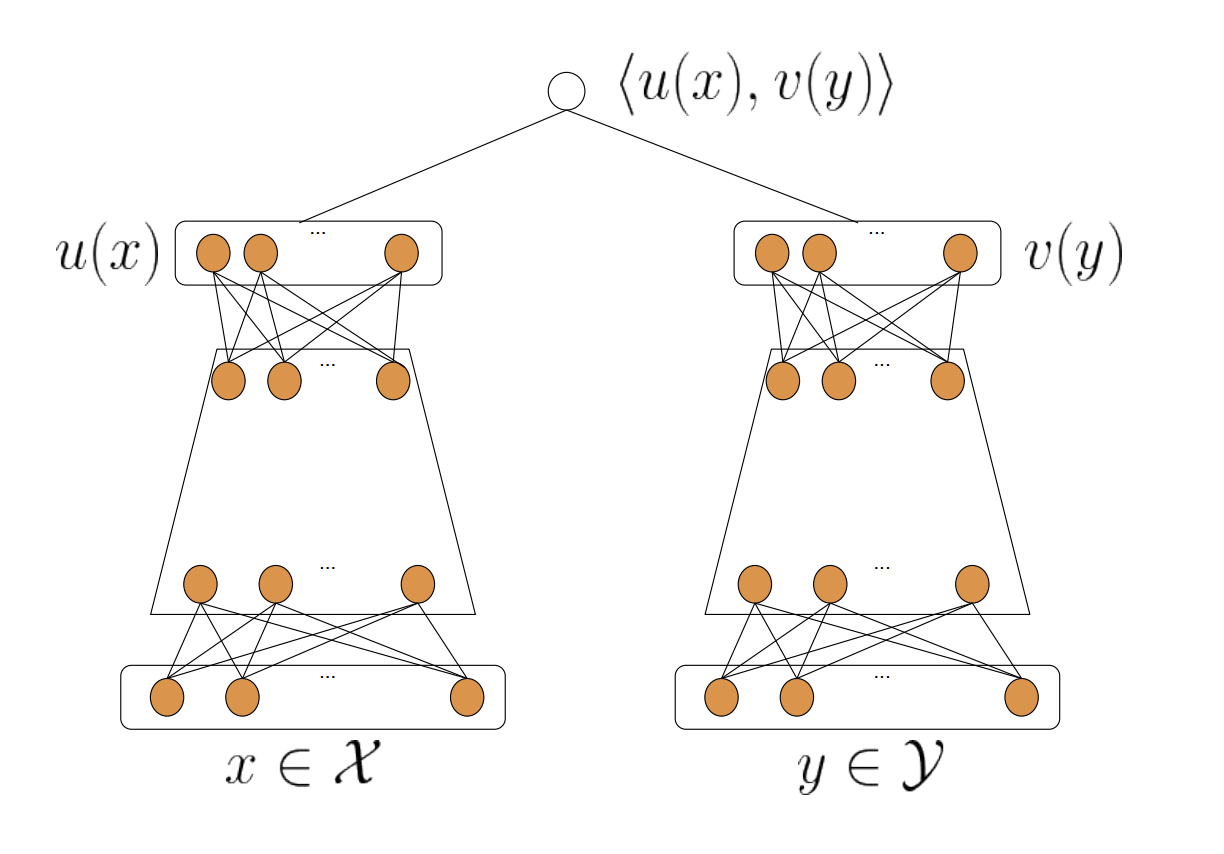
Youtube的双塔召回模型的架构 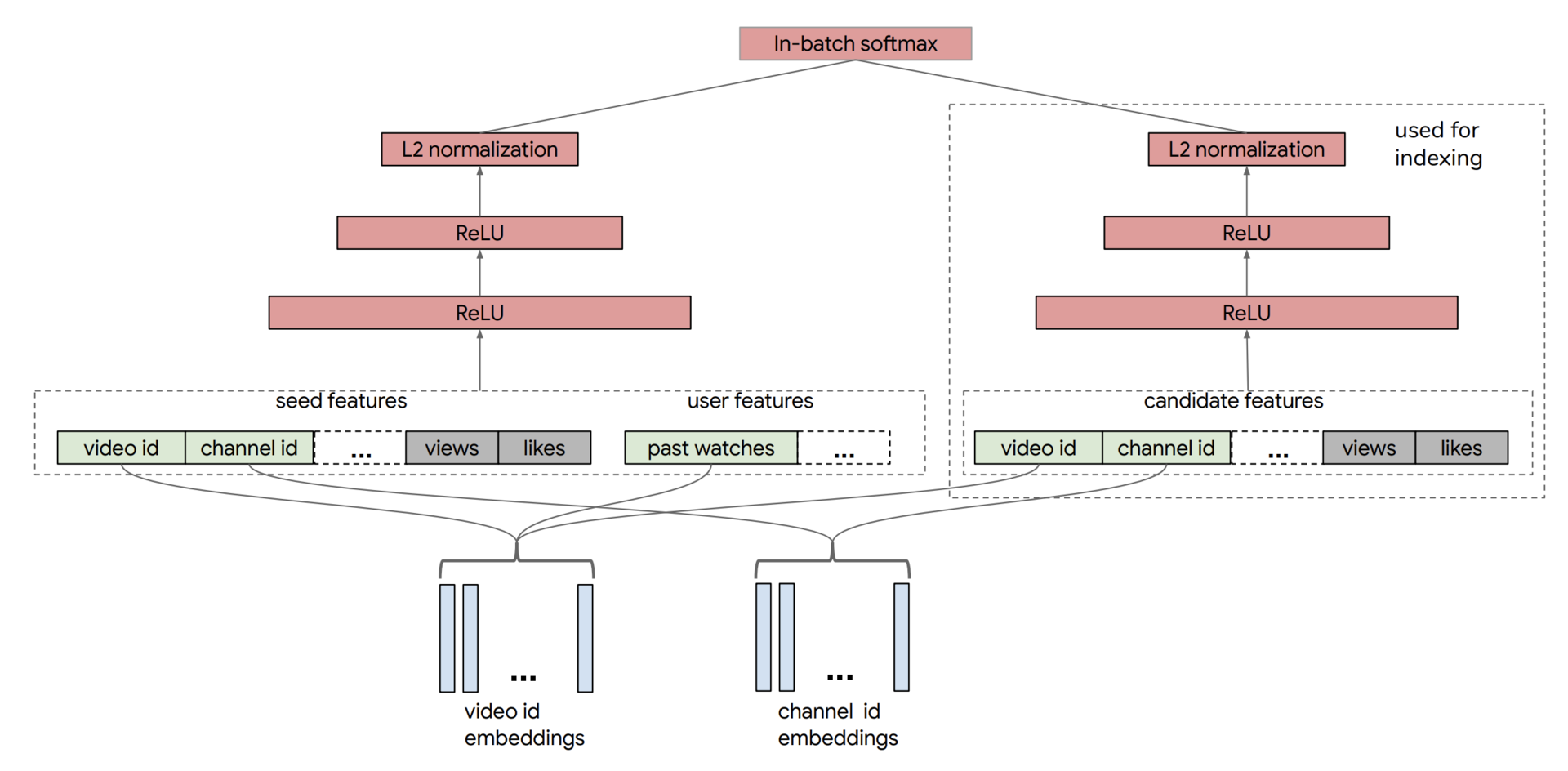
NeuralCF 的模型结构之中,蕴含了一个非常有价值的思想,就是我们可以把模型分成用户侧模型和物品侧模型两部分,然后用互操作层把这两部分联合起来,产生最后的预测得分。
只要是这种物品侧模型 + 用户侧模型 + 互操作层的模型结构,我们把它统称为“双塔模型”结构。
这个双塔模型相比我们之前学过的 Embedding MLP 和 Wide&Deep 有什么优势呢?其实在实际工作中,双塔模型最重要的优势就在于它易上线、易服务。
流程:把计算出来的 u(x) 和 v(y) 存入特征数据库,这样一来,线上服务的时候,我们只要把 u(x) 和 v(y) 取出来,再对它们做简单的互操作层运算就可或者模型预估。
正是因为这样的优势,双塔模型被广泛地应用在 YouTube、Facebook、百度等各大公司的推荐场景中,持续发挥着它的能量。
总结
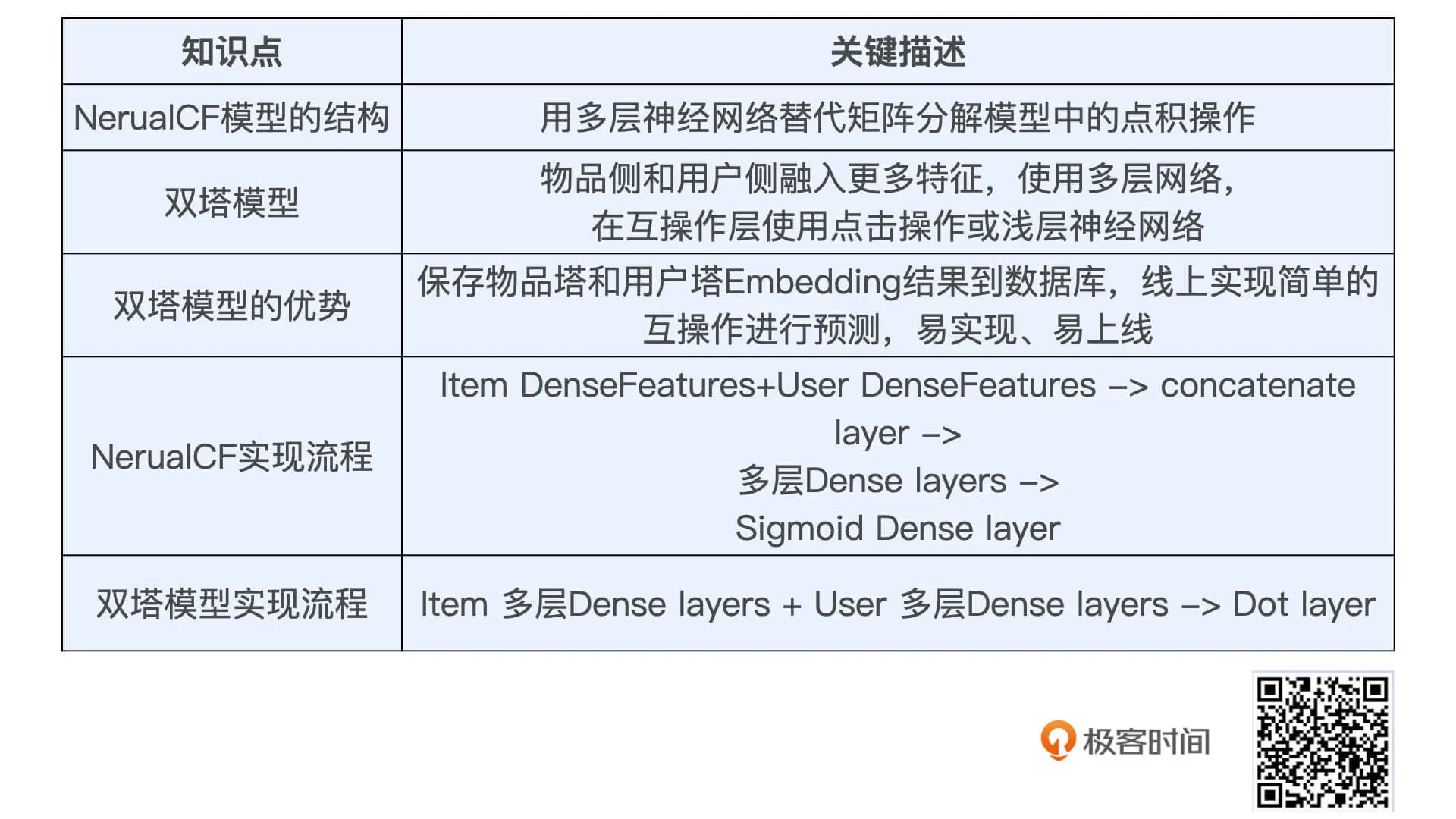
20 | DeepFM:如何让你的模型更好地处理特征交叉?
善于处理特征交叉的机器学习模型 FM。说到解决特征交叉问题的传统机器学习模型,我们就不得不提一下,曾经红极一时的机器学习模型因子分解机模型(Factorization Machine)了,我们可以简称它为 FM。
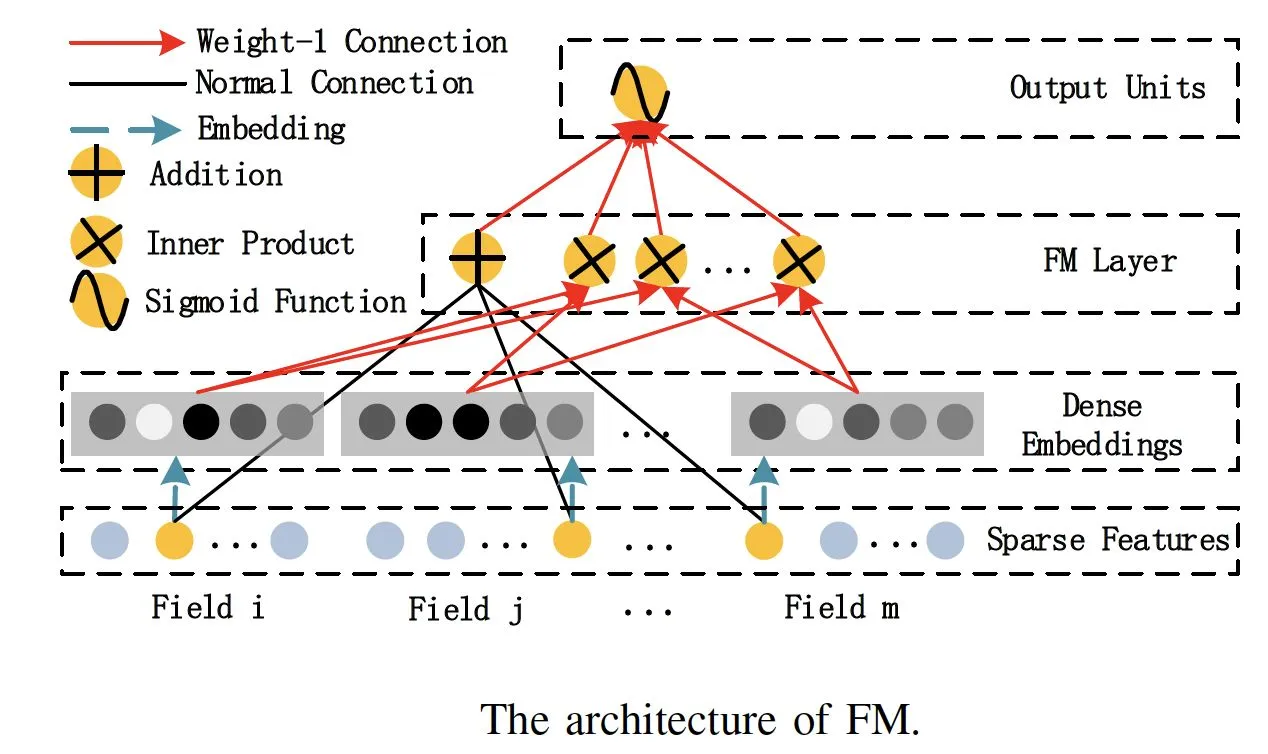
- 输入:类别特征转换从成One-hot向量,
- 把 One-hot 特征通过 Embedding 层转换成稠密 Embedding 向量
- FM Layer层,专门处理特征交叉问题。(通过多个内积单元做交叉)
- 输出。
21|注意力机制、兴趣演化:推荐系统如何抓住用户的心?
什么是“注意力机制”?注意力机制”来源于人类天生的“选择性注意”的习惯。
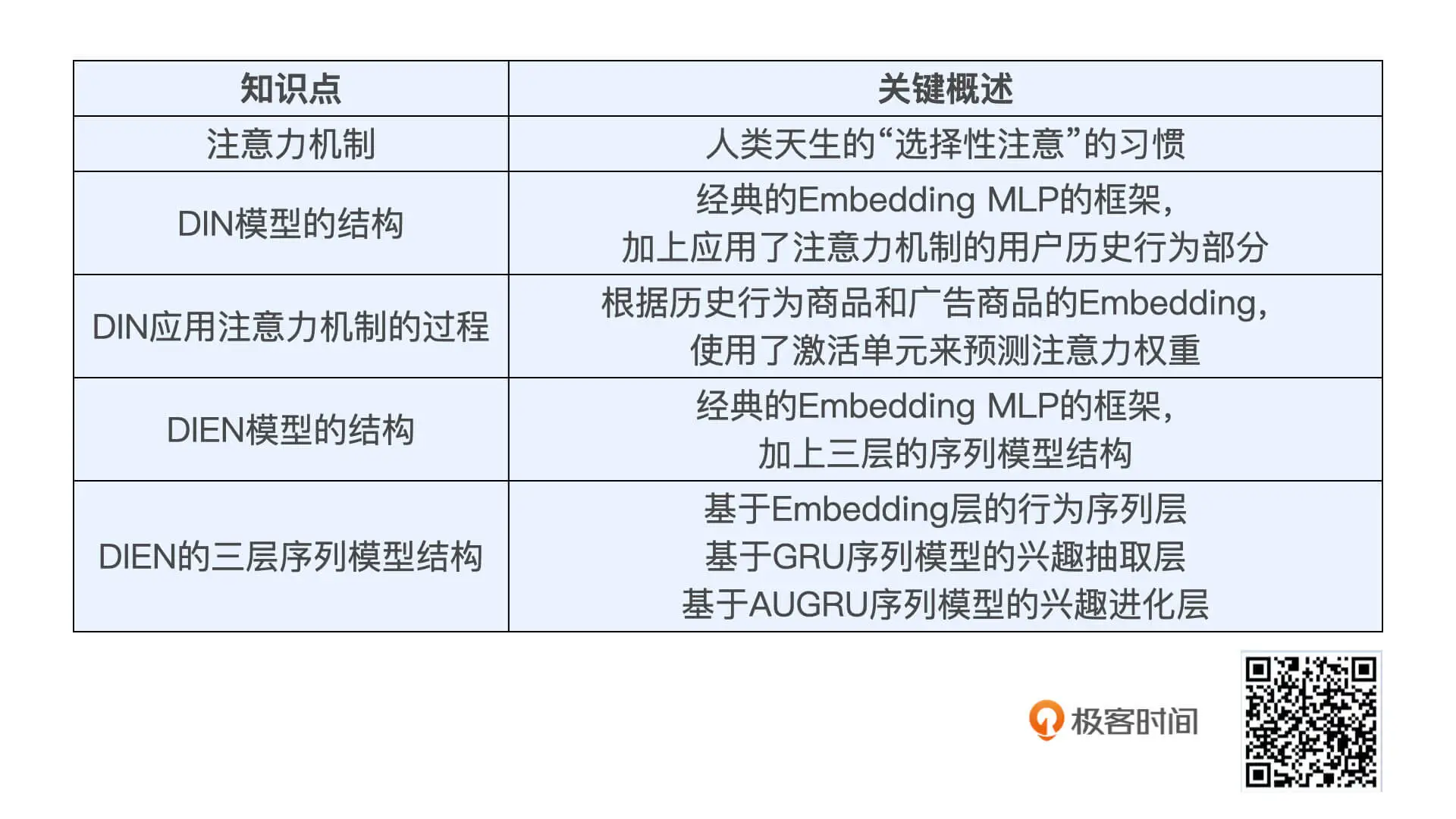
近年注意力机制成功应用在各种推荐系统场景。其中最知名的是阿里的DIN(Deep Interest Network,深度兴趣网络)。
Base Model 是一个典型的 Embedding MLP 的结构。它的输入特征有用户属性特征(User Proflie Features)、用户行为特征(User Behaviors)、候选广告特征(Candidate Ad)和场景特征(Context Features)。
DIN在Base Model基础上,为每个用户的历史购买商品加上了一个激活单元(Activation Unit)。
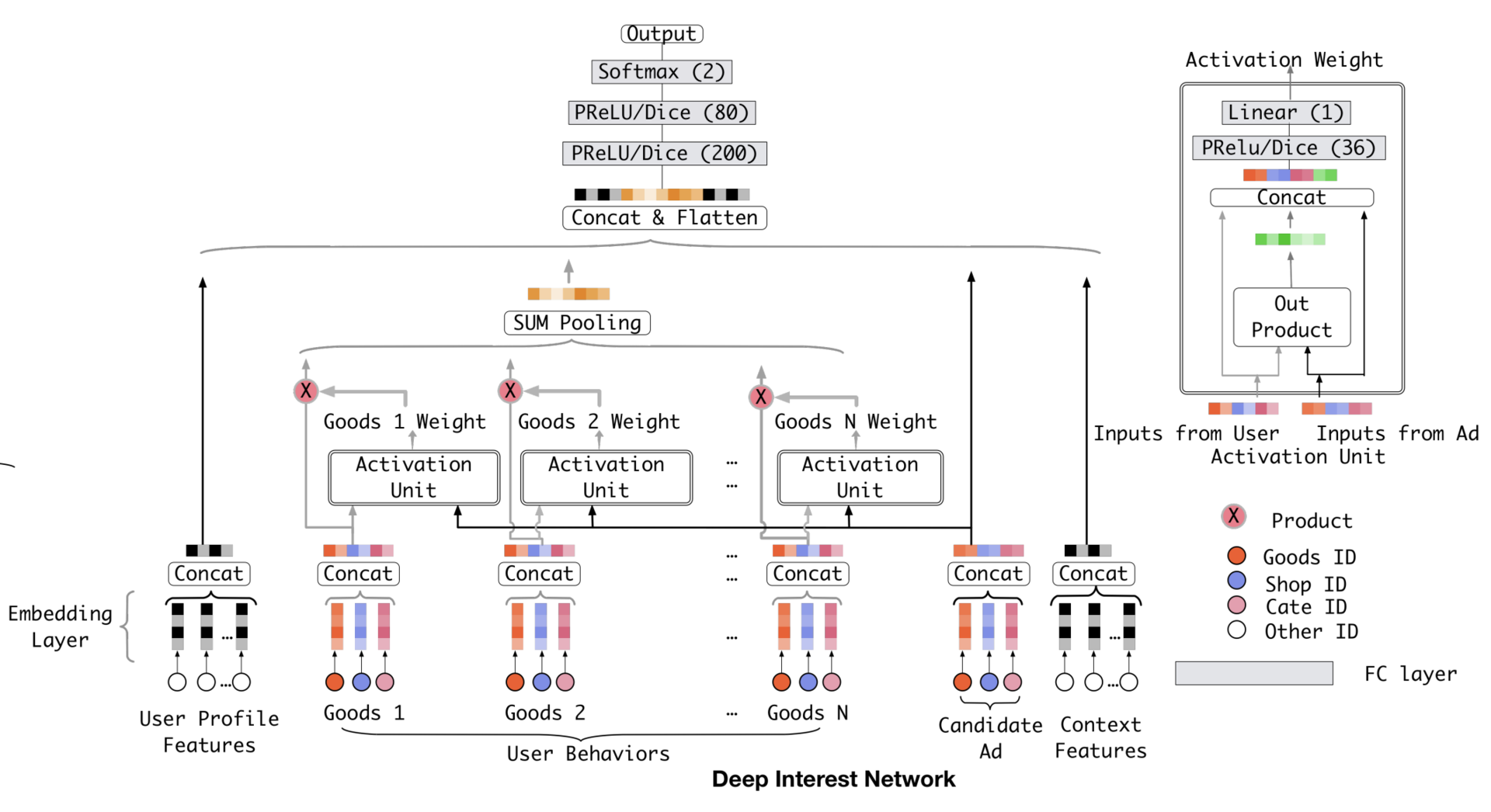
激活单元
输入是:历史行为商品的embedding,及候选广告商品的Embedding,及他们的外积结果形成向量,再输入给激活单元的MLP层,
输出:形成注意力权重。
简单来说,激活单元就相当于一个小的深度学习模型,它利用两个商品的 Embedding,生成了代表它们关联程度的注意力权重。
兴趣进化序列模型
阿里2019年提出了DIN模型的演化版本,也就是深度兴趣进化网络 DIEN(Deep Interest Evolution Network)。
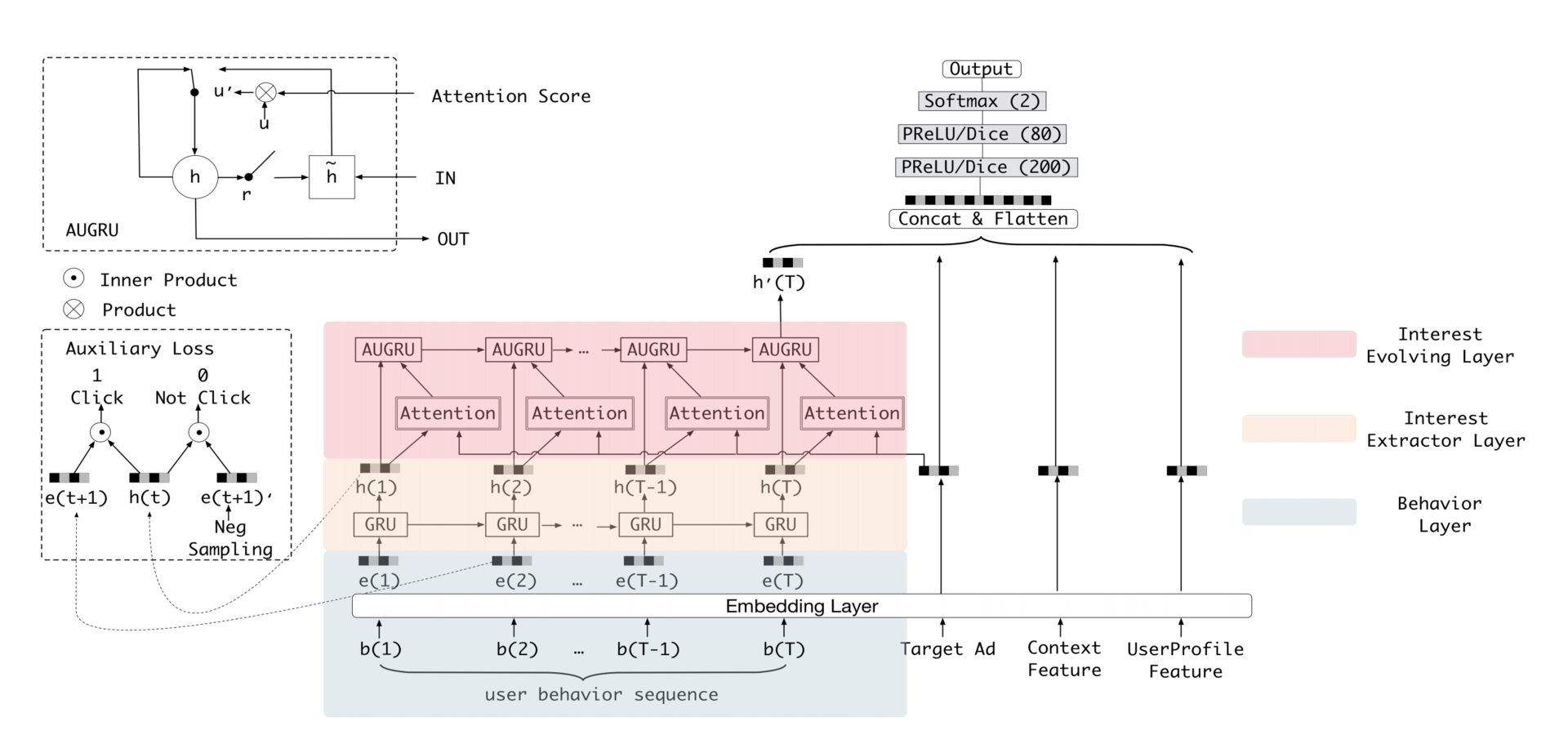
- 最下层行为序列层。Behavior Layer,它的主要作用和一个普通的 Embedding 层是一样的,负责把原始的 ID 类行为序列转换成 Embedding 行为序列。
- 中层兴趣抽取层。Interest Extractor Layer,主要作用是利用 GRU 组成的序列模型,来模拟用户兴趣迁移过程,抽取出每个商品节点对应的用户兴趣。
- 顶层兴趣进化层。Interest Evolving Layer,主要作用是利用 AUGRU(GRU with Attention Update Gate) 组成的序列模型,在兴趣抽取层基础上加入注意力机制,模拟与当前目标广告(Target Ad)相关的兴趣进化过程,兴趣进化层的最后一个状态的输出就是用户当前的兴趣向量 h'(T)。
GRU 序列模型,它其实是序列模型的一种,根据序列模型神经元结构的不同,最经典的有RNN、LSTM、GRU这 3 种。 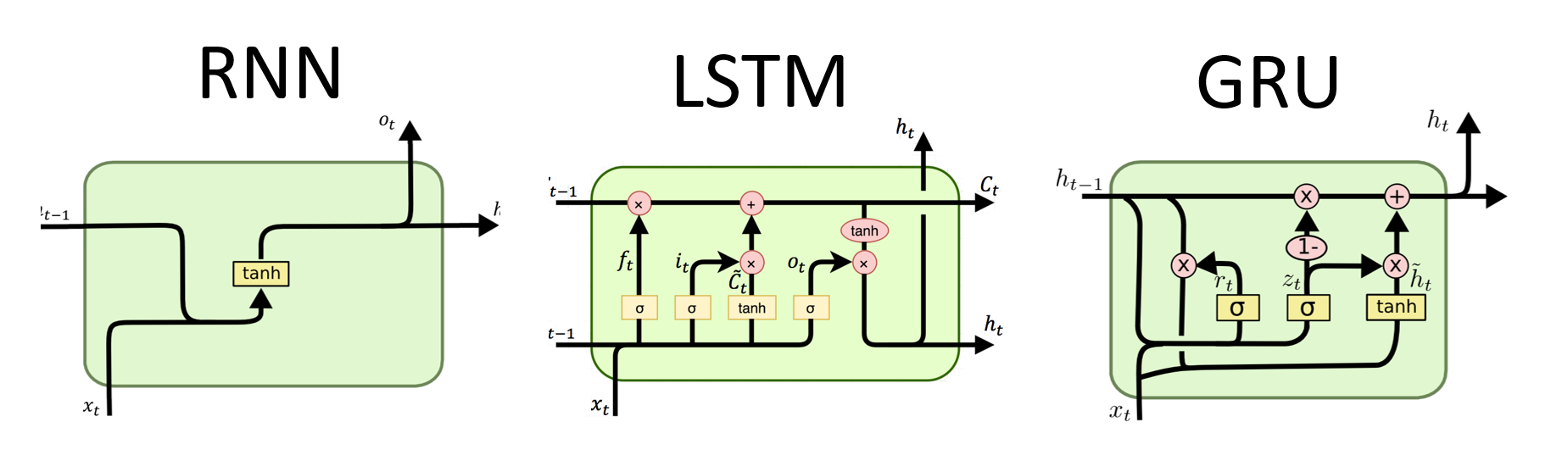
22|强化学习:让推荐系统像智能机器人一样自主学习
强化学习也被称为增强学习。
强化学习的基本原理,简单来说,就是一个智能体通过与环境进行交互,不断学习强化自己的智力,来指导自己的下一步行动,以取得最大化的预期利益。
通用强化学习框架的6要素:
- 智能体 agent
- 环境 env
- action
- reward
- state
- Objective
强化学习推荐模型 DRN(Deep Reinforcement Learning Network,深度强化学习网络)是微软在 2018 年提出的,它被应用在了新闻推荐的场景上。
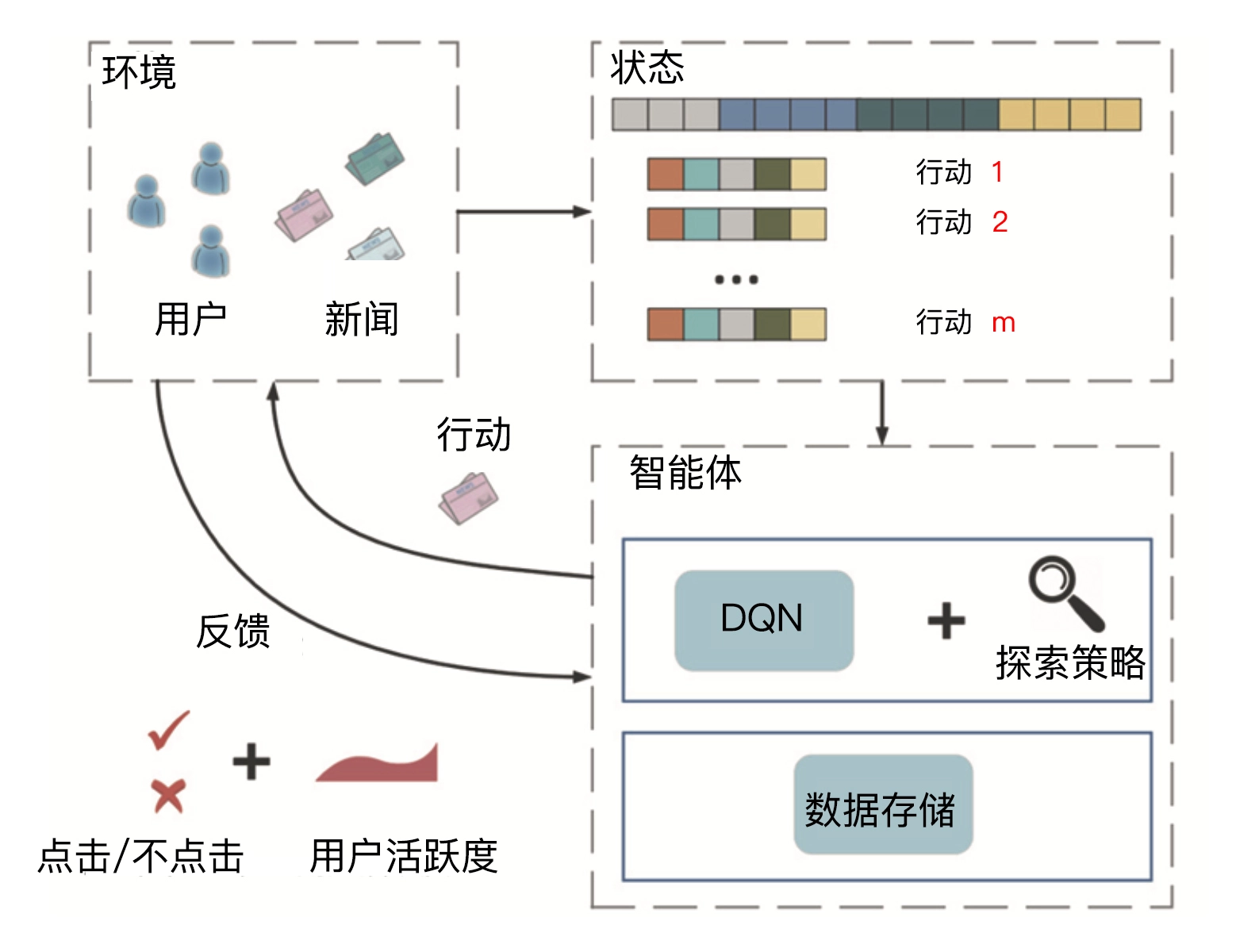

深度强化学习推荐模型 DRN
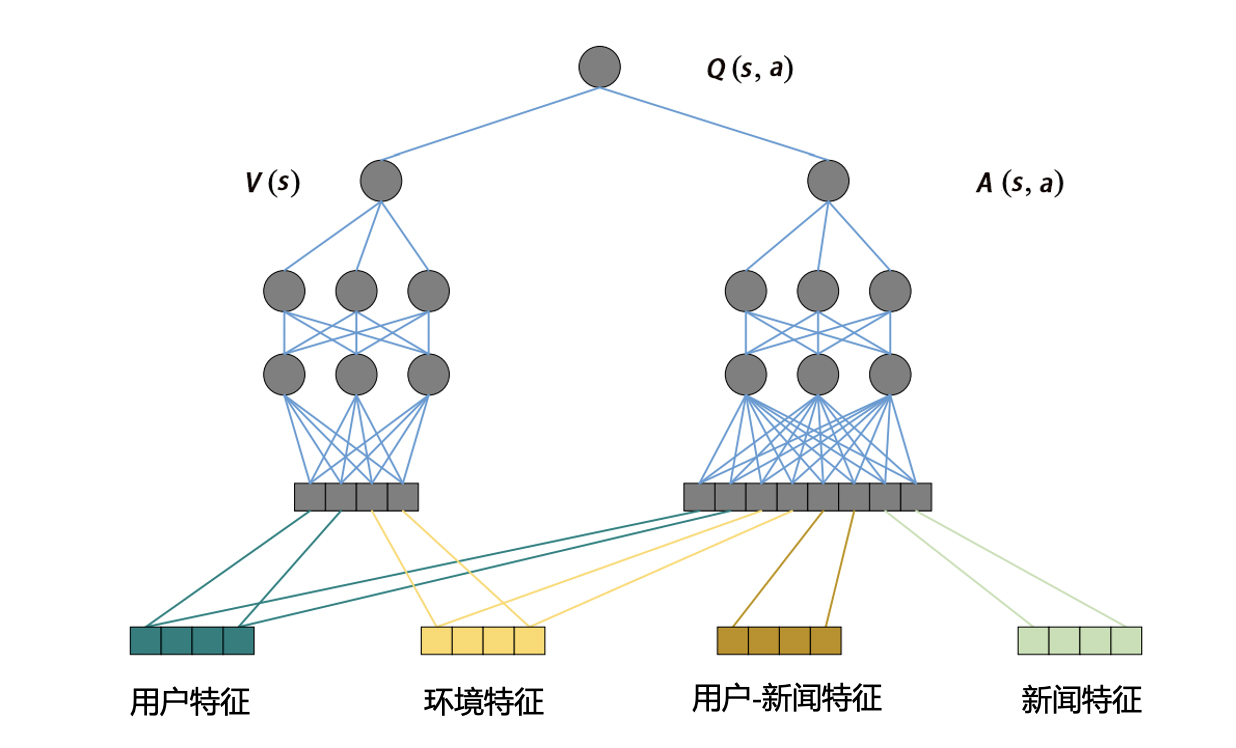
状态向量:用户塔特征向量。
行动向量:物品塔特征向量。
双塔模型 两种向量分别进行MLP,最后互操作层进行行动打分。
DRN学习过程
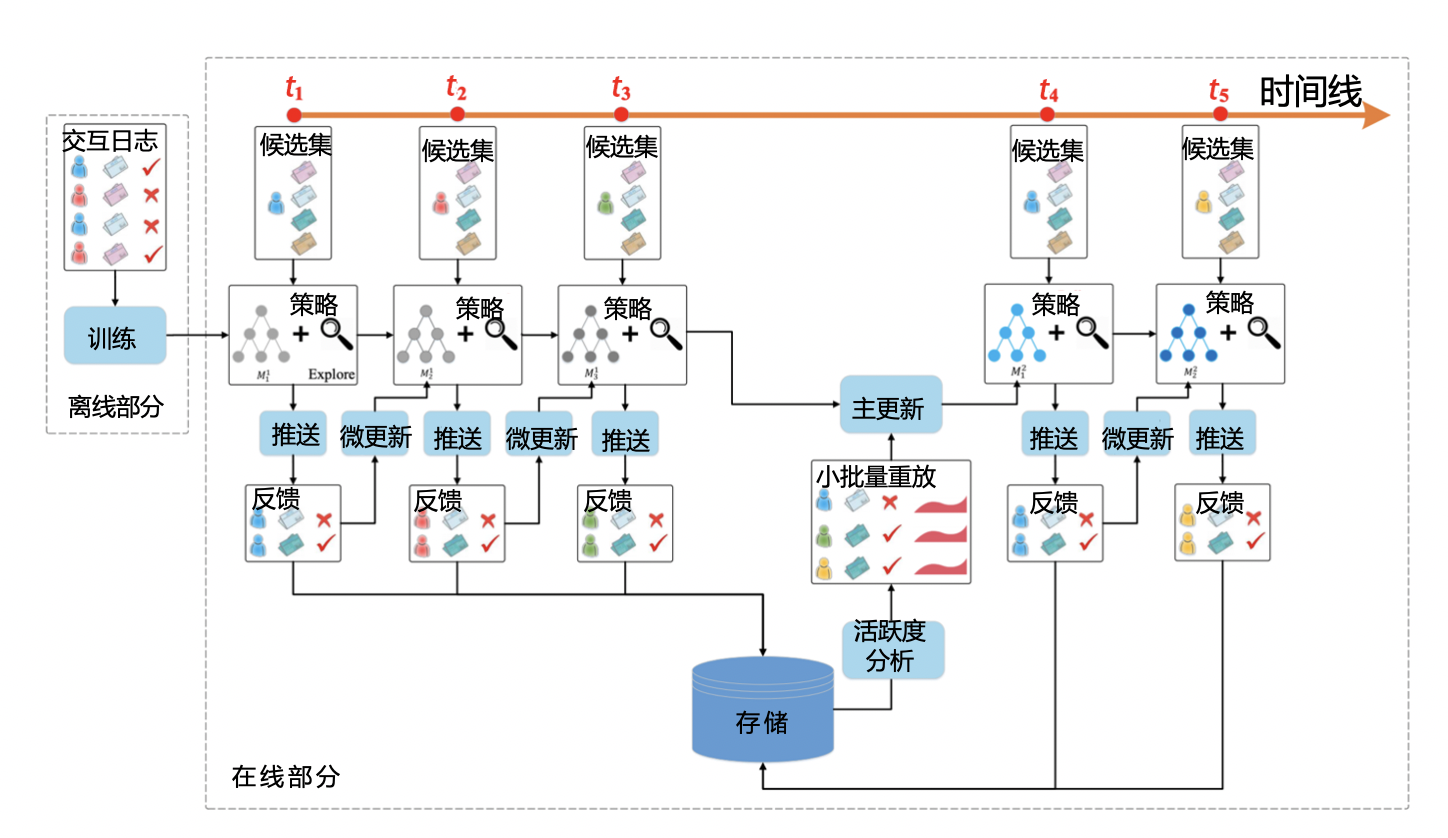
t1到t2进行微更新。微更新:新的在线训练方法,Dueling Bandit Gradient Descent algorithm(竞争梯度下降算法)。
t4进行主更新。可以理解为常规的替代原有模型。
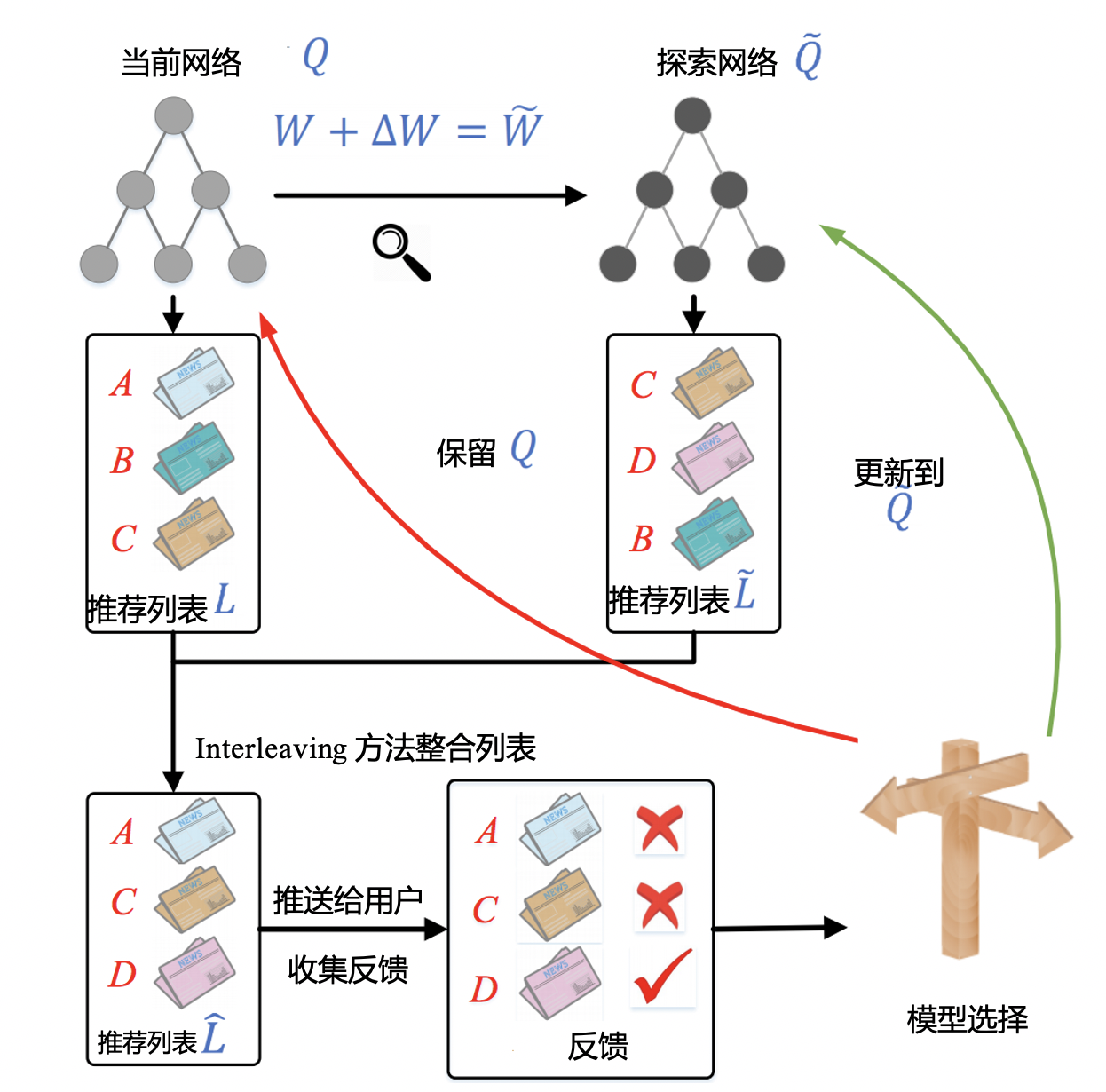
- 第一步,对于已经训练好的当前网络 Q,对其模型参数 W 添加一个较小的随机扰动,得到一个新的模型参数,这里我们称对应的网络为探索网络 Q~。在这一步中,由当前网络Q生成探索网络,
产生随机扰动的公式如下:ΔW=α⋅rand(−1,1)⋅W其中,α 是一个探索因子,决定探索力度的大小。rand(-1,1) 产生的是一个[-1,1]之间的随机数。 - 第二步,对于当前网络 Q 和探索网络 Q~,分别生成推荐列表 L 和 L~,再将两个推荐列表用间隔穿插(Interleaving)的方式融合,组合成一个推荐列表后推送给用户。
- 最后一步是实时收集用户反馈。如果探索网络 Q~生成内容的效果好于当前网络Q,我们就用探索网络代替当前网络,进入下一轮迭代。反之,我们就保留当前网络。
作者认为:它最大的改进就是把模型推断、模型更新、推荐系统工程整个一体化了,让整个模型学习的过程变得更高效,能根据用户的实时奖励学到新知识,做出最实时的反馈。
summary
特别加餐 | “银弹”不可靠,最优的模型结构该怎么找?
有解决推荐问题的“银弹”吗?
没有。
总的来说,通过 DIEN 的例子我们可以得出,到底怎样的模型结构是最优的模型结构,跟你的业务特点和数据特点强相关。因此,在模型结构的选择上,没有“银弹”,没有最优,只有最合适。
在工作中避免学生思维
作者希望:我希望把业界的主流方法告诉你,期望你建立起来的是一套知识体系和方法论.
算法工程师正确的工作方法
- 问题提出
- 数据和业务探索
- 初始解决方案
- 解决方案调优
- 工程落地调整
- 生产环境上线
- 迭代和复盘
做算法工程师,首先要有扎实全面的技术功底,但更重要的其实是自信和务实的精神,不迷信所谓的权威模型,不试图寻找万能的参数,从业务出发,从用户的真实行为出发,才能够构建出最适合你业务场景的推荐模型 。
23| 实战:如何用深度学习模型实现Sparrow RecSys的个性化推荐功能?
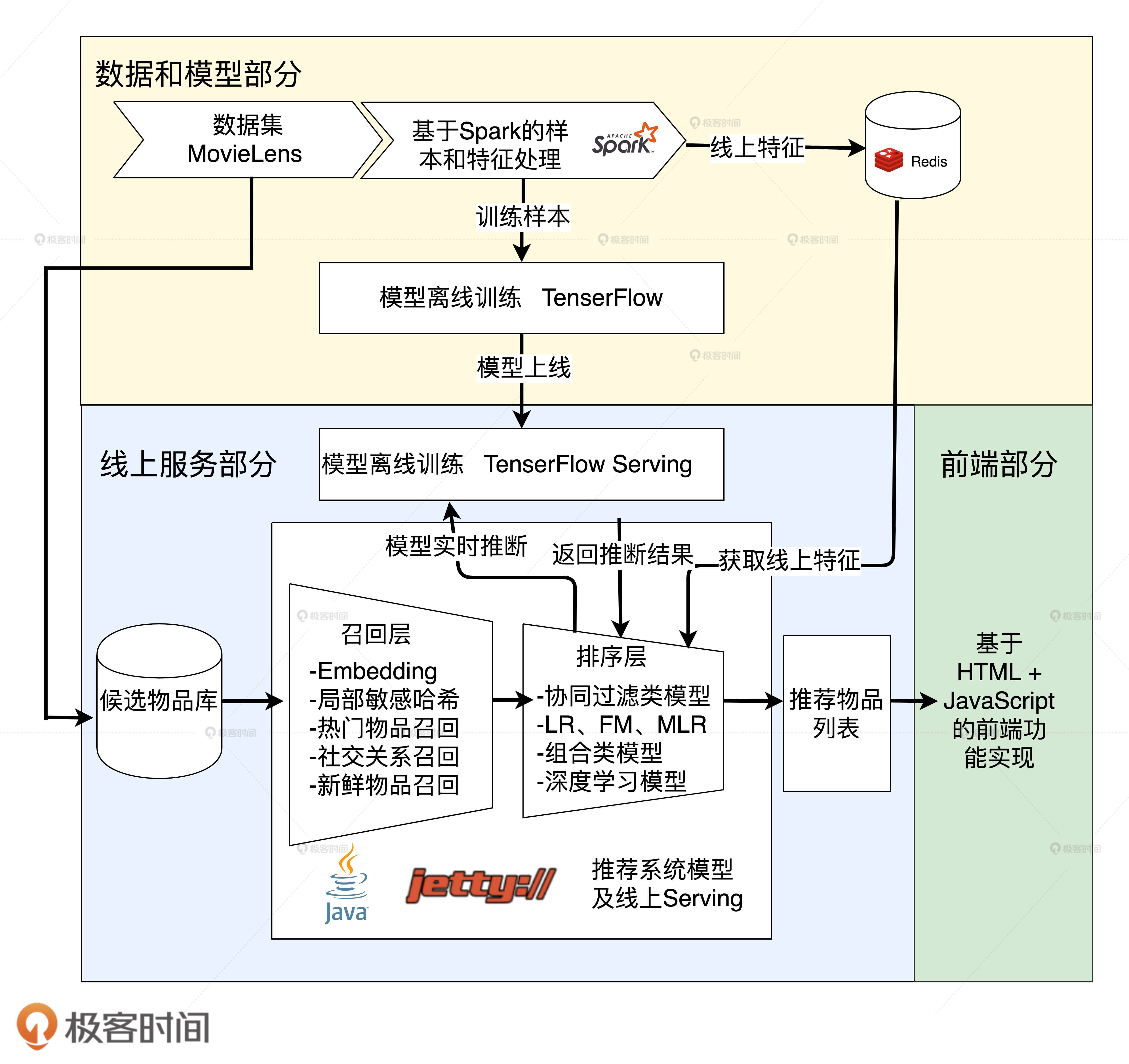
- 源数据集(内容库、线上回收事件),经过Spark的处理,生成两部分数据,
- 样本提供给TensorFlow模型训练
- 特征部分存入Redis供线上推断时,推荐引擎服务使用
- TensorFlow训练完导出模型文件,模型文件载入TensorFlow Serving中,接着TensorFlow Serving开放模型API,供线上推荐引擎服务使用。
- 推荐引擎服务 候选物品获取、召回层、排序层。
模型评估篇
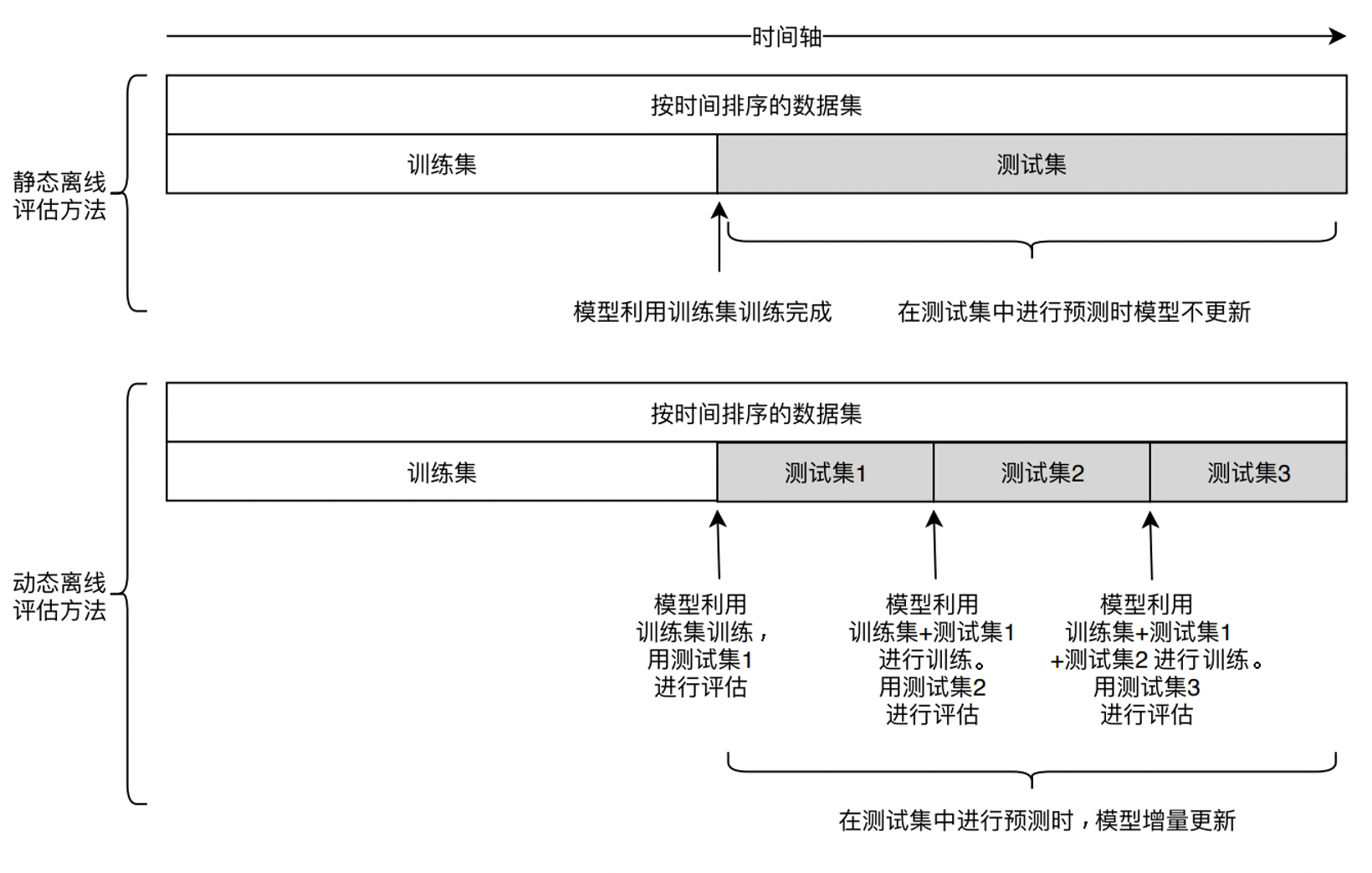
24 | 离线评估:常用的推荐系统离线评估方法有哪些?
离线评估的基本原理是在离线环境下,将数据集分为“训练集”和“测试集”两部分, 训练集训练模型,测试集评估模型。
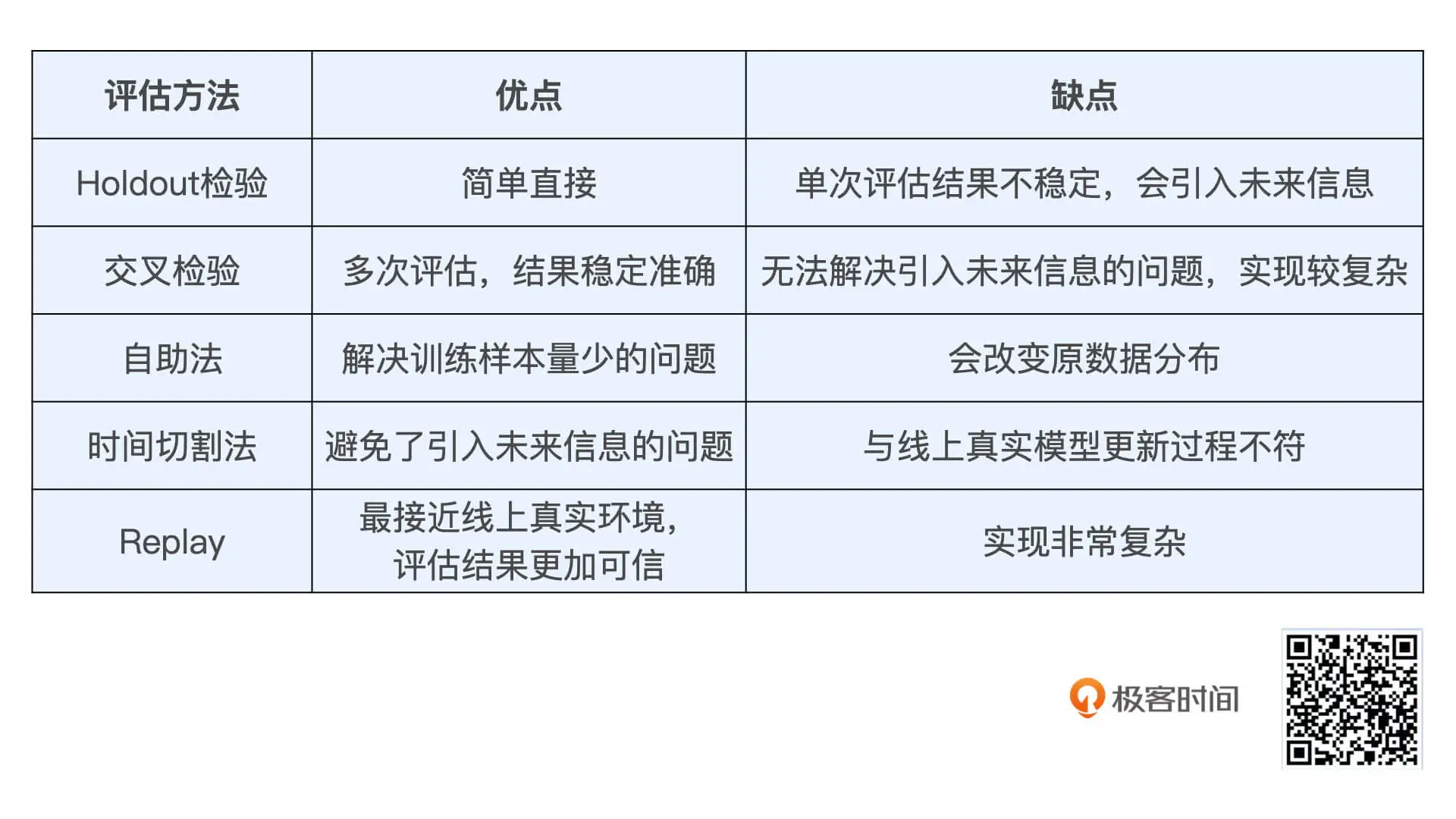
常见用的离线评估方法:
- Holdout检验 随机划分训练集和测试集。
- 交叉检验 取k=10(通常做法),分k个样本集合,依次遍历子集合,当前k作为验证集(测试集)其他作为训练集。该过程循环进行k此次。
- 自助法 当样本较小,可以用自助法做抽取并放回,最后用没有抽取过的集合作为测试验证集。
- 时间切割 训练要防止用未来信息去训练,所以用时间刻度抽取某一时间段,里面一部分作为测试集、一部分作为训练集合。一般1:3、1:10这样的比例。
- 离线replay 动态离线评估。
总结:
25 | 评估指标:我们可以用哪些指标来衡量模型的好坏?
低阶评估指标:
- 准确率 Accuracy=ncorrect/ntotal。
- 精确率和召回率
- 对数损失
- 均方差误差
高阶评估指标:
- P-R曲线
- ROC曲线
- 比如,在对推荐模型的离线评估中,大家默认的权威指标是 ROC 曲线的 AUC。但 AUC 评估的是整体样本的 ROC 曲线,所以我们往往需要补充分析 mAP,或者对 ROC 曲线进行一些改进,我们可以先绘制分用户的 ROC,再进行用户 AUC 的平均等等。
- 平均精度均值mAP(mAP,mean average precision)它除了在推荐系统中比较常用,在信息检索领域也很常用。
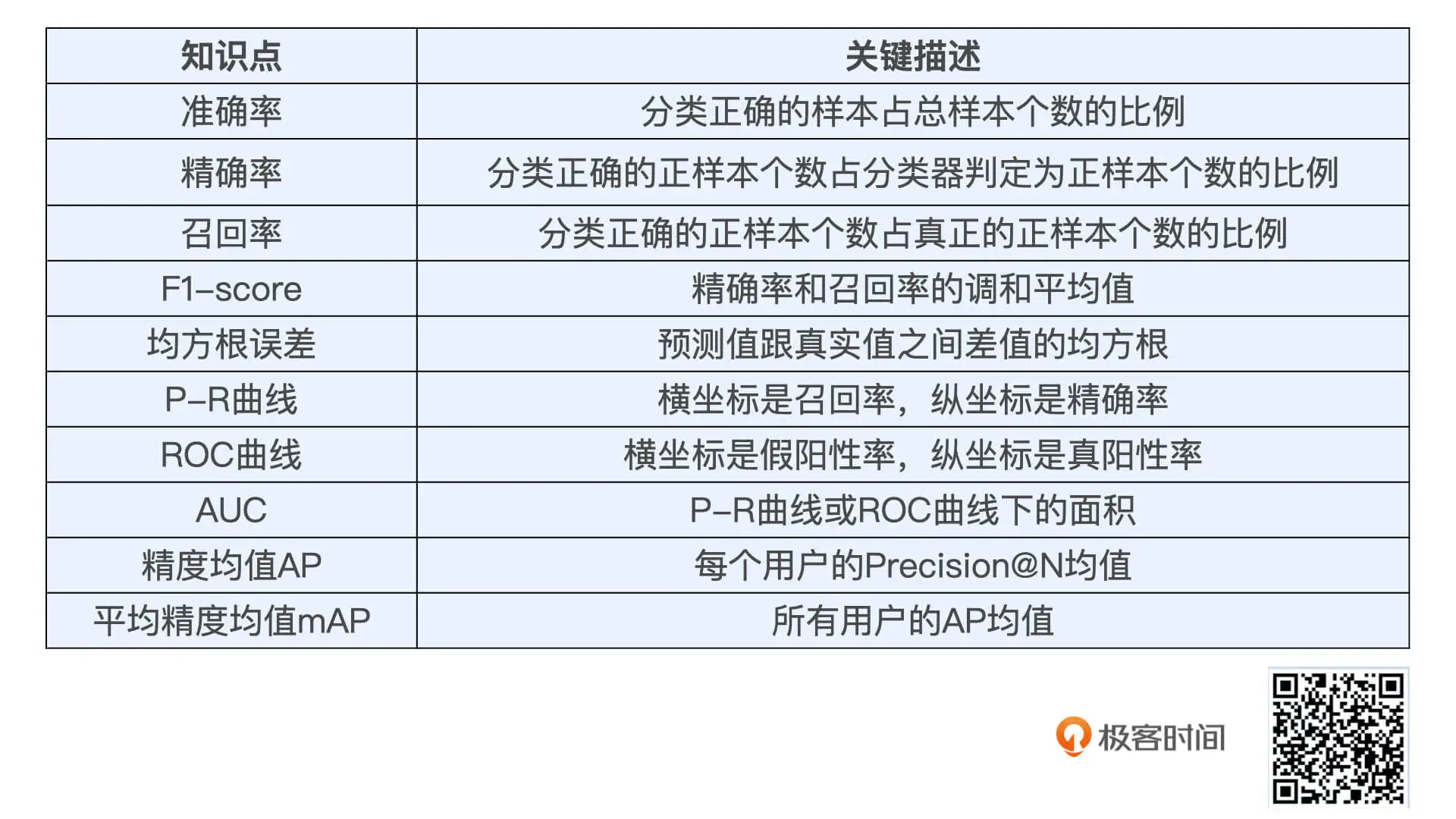 合理选择评估指标, 低阶评估指标主要包括准确率,精确率,召回率和均方根误差。 准确率是指分类正确的样本占总样本个数的比例,精确率指的是分类正确的正样本个数占分类器判定为正样本个数的比例,召回率是分类正确的正样本个数占真正的正样本个数的比例,而均方根误差的定义是预测值跟真实值之间差值的均方根。
合理选择评估指标, 低阶评估指标主要包括准确率,精确率,召回率和均方根误差。 准确率是指分类正确的样本占总样本个数的比例,精确率指的是分类正确的正样本个数占分类器判定为正样本个数的比例,召回率是分类正确的正样本个数占真正的正样本个数的比例,而均方根误差的定义是预测值跟真实值之间差值的均方根。
高阶指标包括 P-R 曲线,ROC 曲线和平均精度均值。 P-R 曲线的横坐标是召回率,纵坐标是精确率;ROC 曲线的横坐标是假阳性率,纵坐标是真阳性率。P-R 曲线和 ROC 曲线的绘制都不容易,我希望你能多看几遍我在课程中讲的例子,巩固一下。最后是平均精度均值 mAP,这个指标是对每个用户的精确率均值的再次平均。
特别加餐|TensorFlow的模型离线评估实践怎么做?
26 | 在线测试:如何在推荐服务器内部实现A/B测试?
A/B 测试的“分桶”和“分层”原则
Google 在一篇关于实验测试平台的论文《Overlapping Experiment Infrastructure: More, Better, Faster Experimentation》中,详细介绍了 A/B 测试分层以及层内分桶的原则。
记住这句话就够了:层与层之间的流量“正交”,同层之间的流量“互斥”。

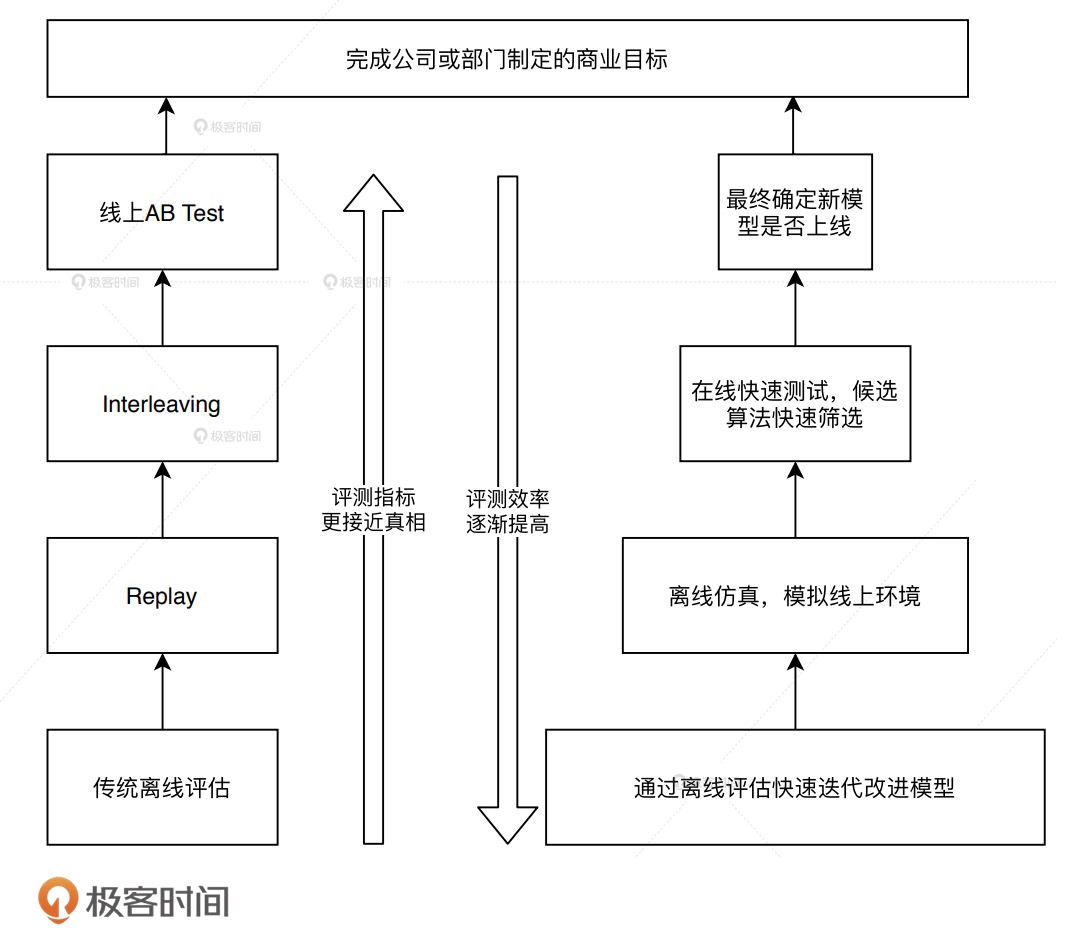
27 | 评估体系:如何解决A/B测试资源紧张的窘境?
线上资源有限ab测试资源有限,不同评估方法有差异和配合问题。--> 建立评估体系。
什么是推荐系统的评估体系?
推荐系统的评估体系指的是,由多种不同的评估方式组成的、兼顾效率和正确性的,一套用于评估推荐系统的解决方案。 一个成熟的推荐系统评估体系应该综合考虑评估效率和正确性,可以利用很少的资源,快速地筛选出效果更好的模型。