《Elasticsearch in action》读书笔记
《Elasticsearch in action》读书笔记
- 作者:Radu Gheorghe
- 出版日期:2018-10
因为本书的es版本是1.x,太老了,所以阅读本书须快速阅读,将本书作为了解es的一个窗口和脉络即可。
第一部分
第1章 Elasticsearch介绍 2
搜索需求的关键词:
- 智能且便捷
- 相关性
- 额外的统计信息、筛选
- 性能
1.1 用Elasticsearch解决搜索问题 3
1.1.1 提供快速查询 3
1.1.2 确保结果的相关性 4
1.1.3 超越精确匹配 5
1.2 探索典型的Elasticsearch使用案例 6
1.2.1 将Elasticsearch作为主要的后端系统 7
1.2.2 将Elasticsearch添加到现有的系统 7
1.2.3 将Elasticsearch和现有工具一同使用 8
1.2.4 Elasticsearch的主要特性 10
1.2.5 扩展Lucene的功能 10
1.2.6 在Elasticsearch中组织数据 12
1.2.7 安装Java语言 12
1.2.8 下载并启动Elasticsearch 13
1.2.9 验证是否工作 14 1.3 小结 16
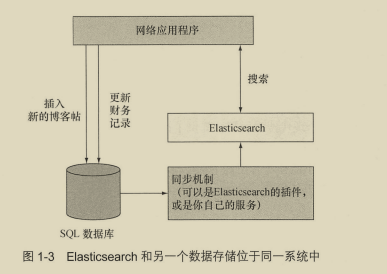
可以考虑将ES作为唯一存储库(生产中一般情况不推荐、除非是允许丢的数据),也可将ES引入现有系统做搜索提速。
ES的主要特性:
- Lucene的索引功能,所有全文搜索能力。 除此之外:
- 聚集功能
- 多索引搜索
- 不同类型文档放一个索引
- Elastic--方便的水平扩缩容
- 分析、分词
总结: 本章说了一些应用场景、特性、安装。
第2章 深入功能 17
2.1 理解逻辑设计:文档、类型和索引 18
2.1.1 文档 19
2.1.2 类型 20
2.1.3 索引 21
逻辑和物理设计: 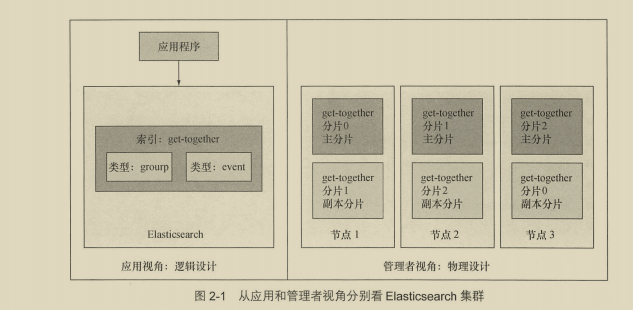
逻辑视图: 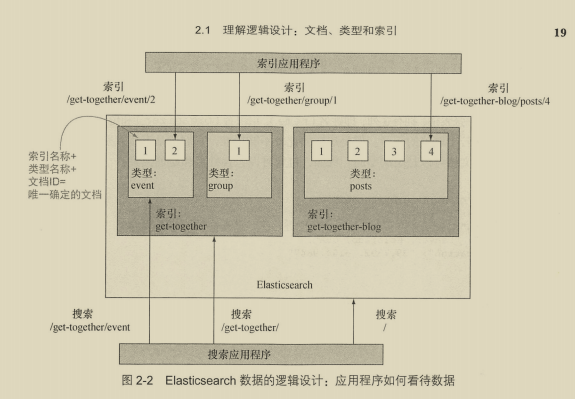
索引名称+类型名称+文档ID=唯一确定的文档
- 自我包含
- 灵活的
- 层次性(可嵌套其他文档)
类型是文档的逻辑容器,类似与表格是行的容器。
索引是映射类型的容器。
2.2 理解物理设计:节点和分片 21
2.2.1 创建拥有一个或多个节点的集群 22 2.2.2 理解主分片和副本分片 23 2.2.3 在集群中分发分片 25 2.2.4 分布式索引和搜索 26
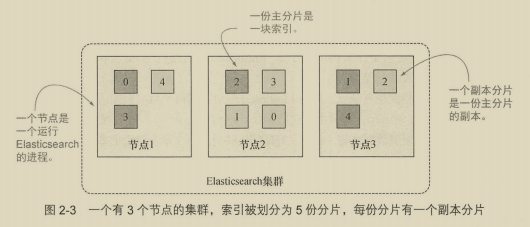 默认情况下,每个索引有5个分片组成,每个主分片有一个副本,一个10个分片。分片是ES将数据从一个节点迁移到另一个节点的最小单位。
默认情况下,每个索引有5个分片组成,每个主分片有一个副本,一个10个分片。分片是ES将数据从一个节点迁移到另一个节点的最小单位。
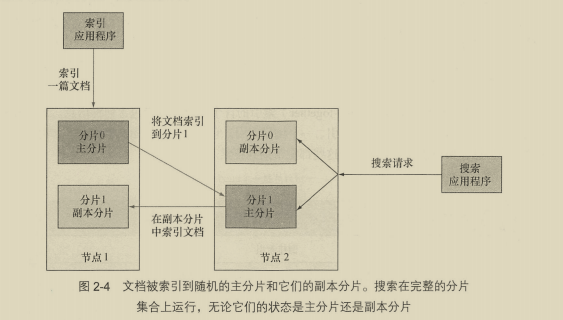
一份分片是一个Lucene索引,所以一个es索引由多个Lucene索引组成。

副本分片可以在运行时添加、删除,主分片不可以。过少分片限制了扩展性,过多影响性能。
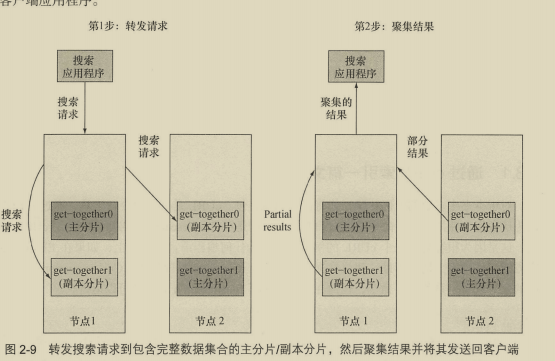
2.3 索引新数据 27
2.3.1 通过cURL索引一篇文档 28 2.3.2 创建索引和映射类型 30 2.3.3 通过代码样例索引文档 31
2.4 搜索并获取数据 32
2.4.1 在哪里搜索 33 2.4.2 回复的内容 33 2.4.3 如何搜索 36 2.4.4 通过ID获取文档 39 2.5 配置Elasticsearch 40 2.5.1 在elasticsearch.yml中指定集群的名称 40 2.5.2 通过logging.yml指定详细日志记录 41 2.5.3 调整JVM设置 41 2.6 在集群中加入节点 42 2.6.1 启动第二个节点 43 2.6.2 增加额外的节点 44 2.7 小结 45
2.4.3 如何搜索 36
- 查询字符串选项
- 使用过滤器:过滤关注于一条结果,在这个场景下性能快。
- 应用聚集
- 通过ID获取文档 已知id场景
第3章 索引、更新和删除数据 47
3.1 使用映射来定义各种文档 48
3.1.1 检索和定义映射 49
3.1.2 扩展现有的映射 50
3.2 用于定义文档字段的核心类型 51
3.2.1 字符串类型 52
3.2.2 数值类型 54
3.2.3 日期类型 55
3.2.4 布尔类型 56
3.3 数组和多字段 56
3.3.1 数组 56
3.3.2 多字段 57
3.4 使用预定义字段 58
3.4.1 控制如何存储和搜索文档 59
3.4.2 识别文档 61
3.5 更新现有文档 63
3.5.1 使用更新API 64
3.5.2 通过版本来实现并发控制 66
3.6 删除数据 69
3.6.1 删除文档 70
3.6.2 删除索引 71
3.6.3 关闭索引 72
3.6.4 重新索引样本文档 73
3.7 小结 73
三种字段类型:
- 核心: 字符串类型、数值类型、日期类型、布尔类型
- 数组和多元字段:数组(文章介绍这里时候,介绍了analyzed、not_analyzed去查询tag)、多字段
- 预定义 _开头的字段,_ttl, _timestamp,_source, _all, _id, _type,_route(控制文档路由), _uid(由id和type组成)等等。
ES采用版本控制(乐观锁)去对并发操作做控制。
第4章 搜索数据 74
该章节大多是一些很有用的使用方法和案例,这里不一一总结,建议使用时候翻阅。
4.1 搜索请求的结构 75
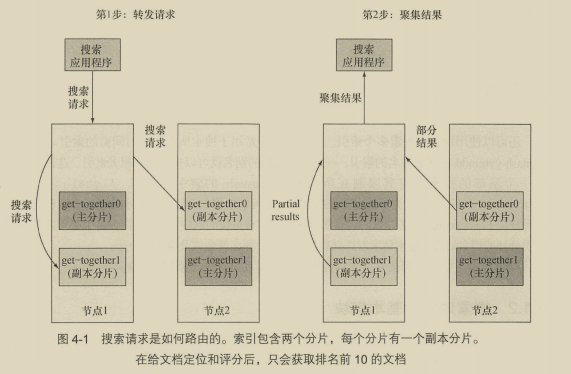
4.1.1 确定搜索范围 75 4.1.2 搜索请求的基本模块 76
4.1.3 基于请求主体的搜索请求 78
4.1.4 理解回复的结构 81
4.2 介绍查询和过滤器DSL 82
忽略得分计算的话,过滤器可以加速查询。
4.2.1 match查询和term过滤器 82
4.2.2 常用的基础查询和过滤器 85
4.2.3 match查询和term过滤器 91
- 布尔查询行为
- 词组查询
4.2.4 phrase_prefix查询 92
4.3 组合查询或复合查询 93
组合多种条件,类似于sql的where里多个条件。
4.3.1 bool查询 93 4.3.2 bool过滤器 96
4.4 超越match和过滤器查询 98
范围查询、wildcard查询
4.4.1 range查询和过滤器 98
4.4.2 prefix查询和过滤器 99
4.4.3 wildcard查询 100
4.5 使用过滤器查询字段的存在性 102
存在查询
4.5.1 exists过滤器 102 4.5.2 missing过滤器 102
4.5.3 将任何查询转变为过滤器 103
_cache能够缓存过滤器。
4.6 为任务选择最好的查询 104

4.7 小结 105
第5章 分析数据 106
重点:
为什么query_string能够灵活搜索。
5.1 什么是分析 106
在文档加入索引前,经过一系列处理:
- 字符过滤
- 文本切分为分词
- 分词过滤
- 分词索引
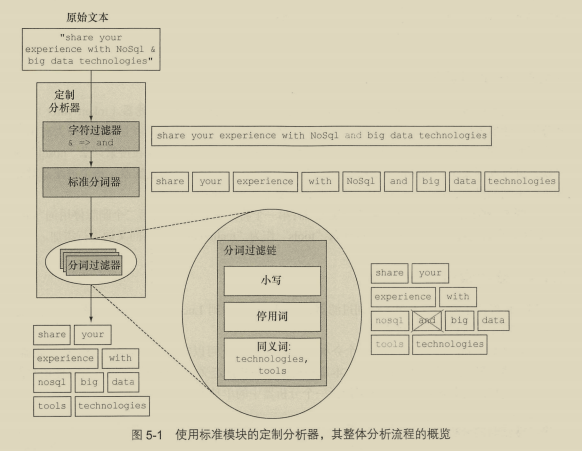
5.1.1 字符过滤 107
5.1.2 切分为分词 108
5.1.3 分词过滤器 108
5.1.4 分词索引 108
5.2 为文档使用分析器 109
该节说了如何指定分析器。
5.2.1 在索引创建时增加分析器 109
5.2.2 在Elasticsearch的配置中添加分析器 111
5.2.3 在映射中指定某个字段的分析器 112
5.3 使用分析API来分析文本 113 5.3.1 选择一个分析器 114
5.3.2 通过组合即兴地创建分析器 115
通过API自行对输入分词。
5.3.3 基于某个字段映射的分析 115
5.3.4 使用词条向量API来学习索引词条 116
5.4 分析器、分词器和分词过滤器 117
5.4.1 内置的分析器 117
- 标准分析器
- 简单分析器
- 空白分析器
- 停用词分析器
- 关键词分析器
- 模式分析器
- 语言与多语言分析器
- 雪球分析器
5.4.2 分词器 119
分词是将字符串分为小块,而小块称为分词(token)。
- 标准分词器
- 关键词分词器
- 字母分词器
- 小写分词器
- 空白分词器
- 模式分词器
- UAX URL电子邮件分词器
- 路径层次分词器
5.4.3 分词过滤器 122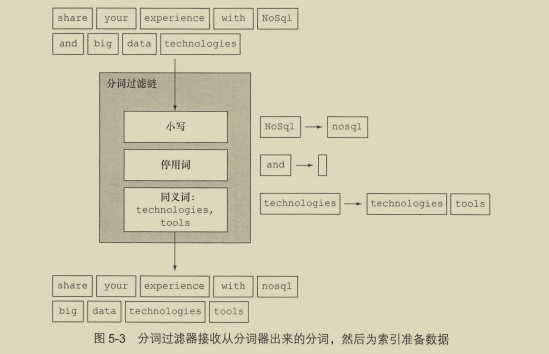
- 标准分词过滤器
- 小写分词过滤器
- 长度分词过滤器
- 停用词分词过滤器
- 截断分词过滤器、修剪分词过滤器、限制分词数量过滤器
- 颠倒分词过滤器
- 唯一分词过滤器
- ASCII折叠分词过滤器
- 同义词分词过滤器
5.5 N元语法、侧边N元语法和滑动窗口 128
这里介绍ES更独特的N元分词方式。
5.5.1 一元语法过滤器 128
5.5.2 二元语法过滤器 129
5.5.3 三元语法过滤器 129
5.5.4 设置min_gram和max_gram 129
5.5.5 侧边N元语法过滤器 129
5.5.6 N元语法的设置 130
5.5.7 滑动窗口分词过滤器 131
5.6 提取词干 132
5.6.1 算法提取词干 133
5.6.2 使用字典提取词干 133
5.6.3 重写分词过滤器的词干提取 134
5.7 小结 134
第6章 使用相关性进行搜索 136
ES和一般sql存储查询引擎不同的是,为文档分配相关性打分能力。
6.1 Elasticsearch的打分机制 137 6.1.1 文档打分是如何运作的 137
ES打分机制称为TF-IDF。词频: TF,逆文档频率:IDF。
6.1.2 词频 137
考虑给一篇文档打分的首要方式是:查看一个词条在文本中的出现频率。
6.1.3 逆文档频率 138
通常一个分词,在文档中出现次数越多,它越不重要。
6.1.4 Lucene评分公式 138
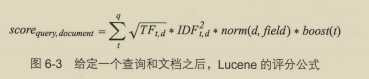
给定查询q和文档d,文档得分是每个词条t的得分总和。
而每个词条t的得分是 词频的平方根 x 逆文档频率的平方 x 归一化因子 x 该词的提升权重。
这种默认打分方式是:TF-IDF和向量空间模型(vector space model)的结合。
6.2 其他打分方法 139
除了主流的TF-IDF模型还有如下模型:
- Okapi BM25
- 随机性分歧,即DFR相似度
- 基于信息的,即IB相似度
- LM Dirichlet相似度
- LM Jelinek Mercer相似度
6.3 boosting 141
建议使用查询期间的boosting
6.3.1 索引期间的boosting 142
6.3.2 查询期间的boosting 142 6.3.3 跨越多个字段的查询 143
6.4 使用“解释”来理解文档是如何被评分的 144
加上explain=true可以查看文档得分情况。 explain还能查看为什么当前查询查不出来某个docid文档。
6.5 使用查询再打分来减小评分操作的性能影响 147
6.6 使用function_score来定制得分 148
一个很cool的功能。
6.6.1 weight函数 149
6.6.2 合并得分 150
6.6.3 field_value_factor函数 151
6.6.4 脚本 152
groovy脚本
6.6.5 随机 152
6.6.6 衰减函数 153
6.6.7 配置选项 155
6.7 尝试一起使用它们吧 156
书中这个例子挺好的,使用时可再看。
6.8 使用脚本来排序 157
脚本排序
6.9 字段数据 158
6.9.1 字段数据缓存 158
6.9.2 字段数据用在哪里 159
6.9.3 管理字段数据 160
- 限制字段数据内容量
- 断路器
- 使用doc value避免内存使用
- 非分析性字段,且希望使用文档值,可以在mapping时指定doc_values=true。 6.10 小结 163
第7章 使用聚集来探索数据 164
有些时候,用户不是需要搜索,而是需要一组文档的统计数据。
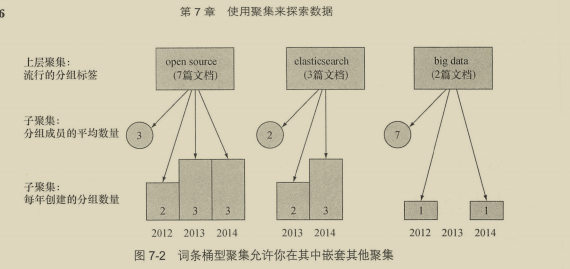
7.1 理解聚集的具体结构 166
- 使用json请求,通过aggregations标记
- 运行在查询结果之上。
- 可以使用过滤器
7.1.1 理解聚集请求的结构 166
7.1.2 运行在查询结果上的聚集 168
7.1.3 过滤器和聚集 169
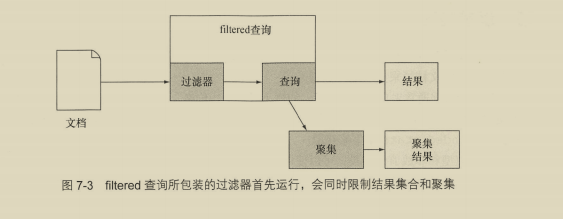
7.2 度量聚集 170
7.2.1 统计数据 171
7.2.2 高级统计 172
7.2.3 近似统计 173
7.3 多桶型聚集 176
种类:
- 词条聚集,返回每个词条出现的次数。
- 范围聚集,
- 直方图聚集,
- 嵌套聚集,允许用户根据文档关系来执行聚集
- 地里距离聚集和地理散列格聚集。
7.3.1 terms聚集 177
7.3.2 range聚集 183
7.3.3 histogram聚集 185
7.4 嵌套聚集 187
聚集真正强大之处,是可以组合他们。
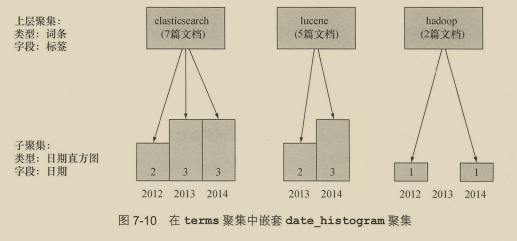
7.4.1 嵌套多桶聚集 189
7.4.2 通过嵌套聚集获得结果分组 190
7.4.3 使用单桶聚集 192
- global聚集
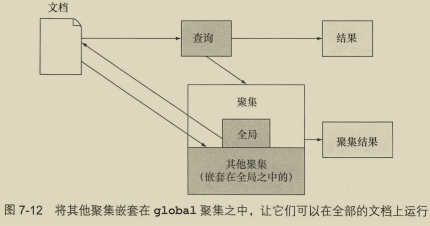
- filter聚集
- missing聚集
7.5 小结 196
第8章 文档间的关系 197
通常分布式系统join是很慢的,而es试图成为实时系统。
本章探索ES文档关系:
- 对象类型
- 嵌套文档
- 父子关系
- 反规范化
- 应用端连接
8.1 定义文档间关系的选项概览 197
8.1.1 对象类型 198
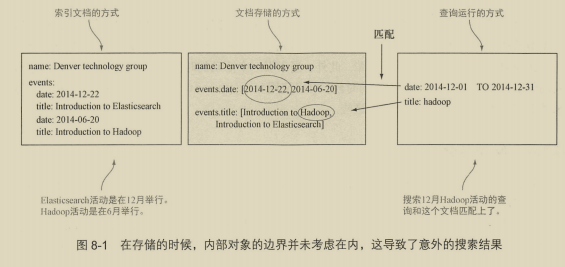
8.1.2 嵌套类型 200
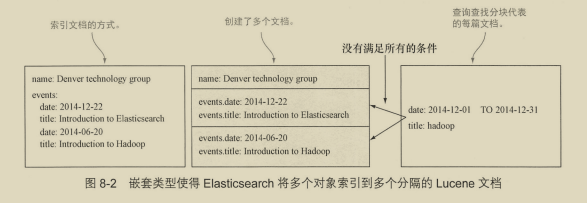
8.1.3 父子关系 200
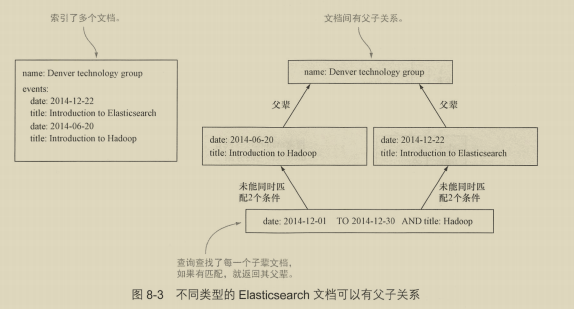
8.1.4 反规范化 200
可以简单理解为是字段冗余存储。
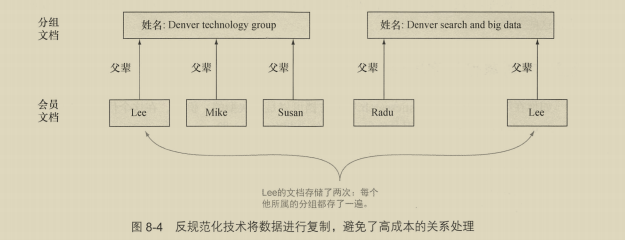
8.2 将对象作为字段值 202 8.2.1 映射和索引对象 203
8.2.1 映射和索引对象 203
8.2.2 在对象中搜索 204
8.3 嵌套类型:联结嵌套的文档 206

8.3.1 映射并索引嵌套文档 207
8.3.2 搜索和聚集嵌套文档 210
8.4 父子关系:关联分隔的文档 216

8.4.1 子文档的索引、更新和删除 218
8.4.2 在父文档和子文档中搜索 220
8.5 反规范化:使用冗余的数据管理 227

8.5.1 反规范化的使用案例 228
8.5.2 索引、更新和删除反规范化的数据 230
8.5.3 查询反规范化的数据 233
8.6 应用端的连接 234
8.7 小结 235
第二部分
关注生产环境
第9章 向外扩展 238
9.1 向Elasticsearch集群加入节点 238
9.2 发现其他Elasticsearch节点 241
9.2.1 通过广播来发现 241
9.2.2 通过单播来发现 242
9.2.3 选举主节点和识别错误 243
9.2.4 错误的识别 244
9.3 删除集群中的节点 245
9.4 升级Elasticsearch的节点 250
9.4.1 进行轮流重启 250
9.4.2 最小化重启后的恢复时间 251
9.5 使用_cat API 252
9.6 扩展策略 254
9.6.1 过度分片 254
9.6.2 将数据切分为索引和分片 255
9.6.3 最大化吞吐量 256
9.7 别名 257
9.7.1 什么是别名 258
9.7.2 别名的创建 259
9.8 路由 261
9.8.1 为什么使用路由 261
9.8.2 路由策略 262
9.8.3 使用_search_shards API来决定搜索在哪里执行 263
9.8.4 配置路由 265
9.8.5 结合路由和别名 265
9.9 小结 267
选主算法,
- ES7前,Bully算法,简单来说,收集节点,选出ID最小的为Master,优点是简单,缺点就是需要控制好配置,可能发生频繁选主.
- ES7后,类Raft算法 分布式共识算法
第10章 提升性能 268
10.1 合并请求 269
10.1.1 批量索引、更新和 删除 269
10.1.2 多条搜索和多条获取 API接口 273
10.2 优化Lucene分段的 处理 276
10.2.1 刷新和冲刷的阈值 276
10.2.2 合并以及合并策略 279
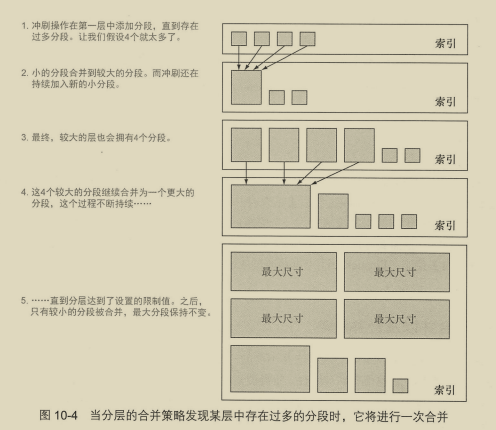
10.2.3 存储和存储限流 282
10.3 充分利用缓存 285
10.3.1 过滤器和过滤器 缓存 285
10.3.2 分片查询缓存 291
10.3.3 JVM堆和操作系统 缓存 293
10.3.4 使用预热器让缓存 热身 296
10.4 其他的性能权衡 297
10.4.1 大规模的索引还是 昂贵的搜索 298
10.4.2 调优脚本,要么 别用它 301
10.4.3 权衡网络开销,更少的 数据和更好的分布式 得分 305
10.4.4 权衡内存,进行深度 分页 308
10.5 小结 310
这一章节,在生产中再次使用时需要多读读。
第11章 管理集群 311
11.1 改善默认的配置 311
11.1.1 索引模板 312
11.1.2 默认的映射 315
11.2 分配的感知 318
本节优化和感知放置数据副本。
11.2.1 基于分片的分配 318
减少az单点故障。
11.2.2 强制性的分配感知 319
11.3 监控瓶颈 320
11.3.1 检查集群的健康 状态 320
有相关的ESAPI可以检测性能。
11.3.2 CPU:慢日志、热线程和 线程池 322
11.3.3 内存:堆的大小、字段和 过滤器缓存 326
11.3.4 操作系统缓存 330
11.3.5 存储限流 330
11.4 备份你的数据 331
11.4.1 快照API 331
可通过API备份到具体网络卷。
11.4.2 将数据备份到共享的文件系统 332
11.4.3 从备份中恢复 335
11.4.4 使用资料库插件 336
11.5 小结 337
附录
附录A 处理地理空间的数据(网上下载)
附录B 插件(网上下载)
附录C 高亮(网上下载)
附录D Elasticsearch的监控插件(网上下载)
附录E 使用渗滤器将搜索颠倒过来(网上下载)